1 算法原理,2qmt常见问题,3算法原理,4量化研报,5 ptrad常见问题,6 因子分析,7 读量化研报
遗传规划简介

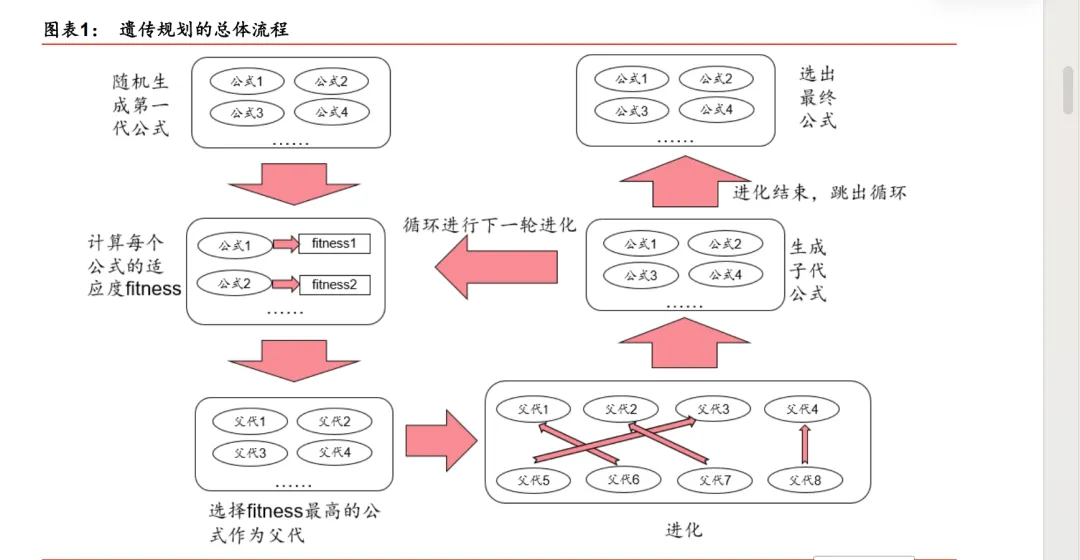
遗传规划的总体流程
图表 1 展示了遗传规划的总体流程。一开始,一组未经选择和进化的原始公式会被随机生成(第一代公式),通过某种规则计算每个公式的适应度,从中选出适合的个体作为下一代进化的父代。这些被选择出来的父代通过多种方法进化,形成不同的后代公式,然后循环进行下一轮进
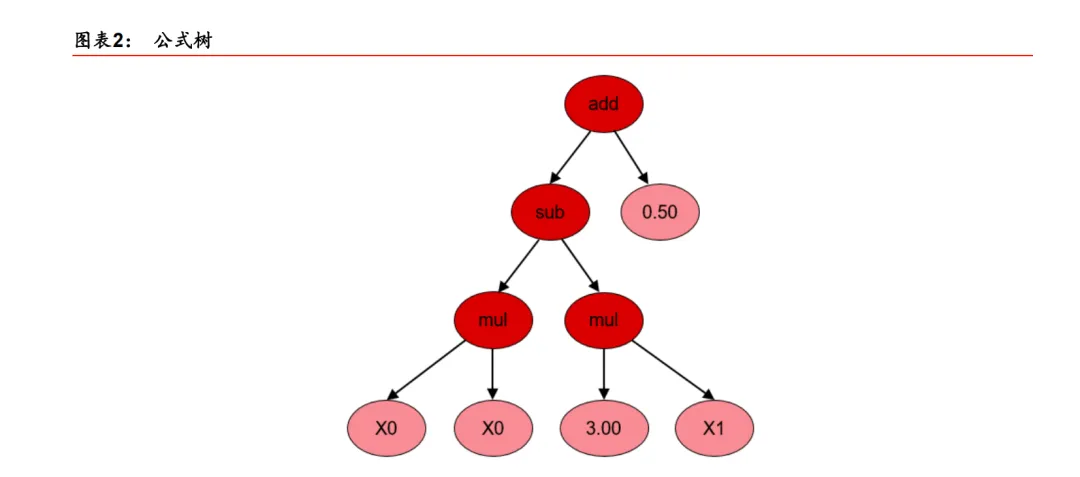
遗传规划中公式的表示方式



交叉
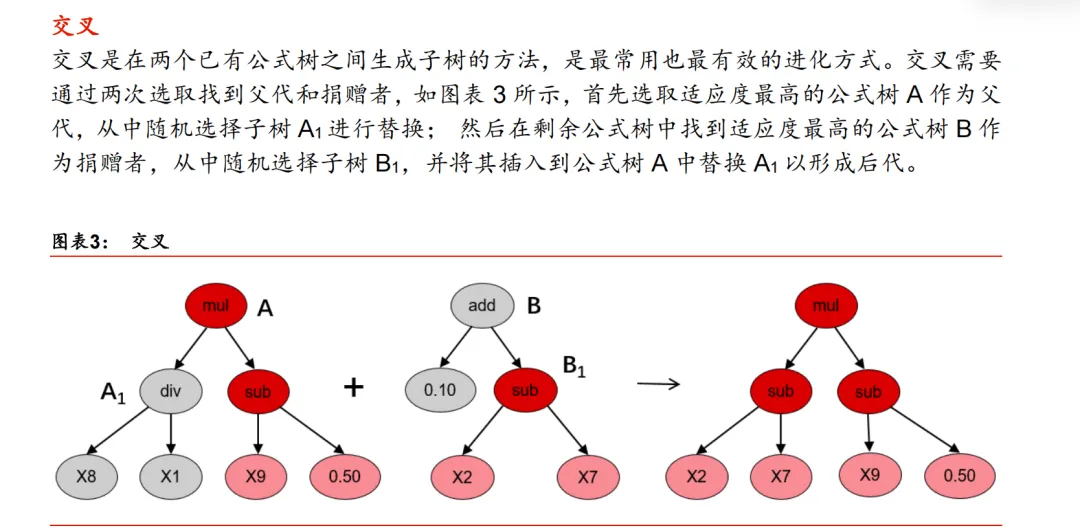
子树变异
子树变异是一种激进的变异操作,父代公式树的子树可以被完全随机生成的子树所取代。这可以将已被淘汰的公式重新引入公式种群,以维持公式多样性。如图表 4 所示,子树变异选择适应度最高的公式树 A 作为父代,从中随机选择子树 A1进行替换,然后随机生成用以替代的子树 B,并将其插入到公式树 A 中以形成后代
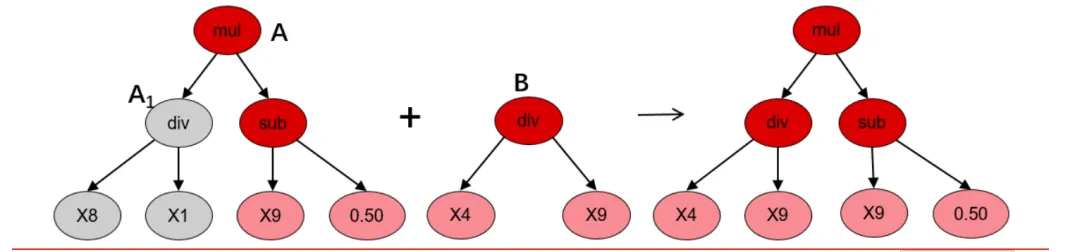
点变异
点变异是另一种常见的变异形式。与子树变异一样,它也可以将已淘汰的公式重新引入种群中以维持公式多样性。如图表 5 所示,点变异选取适应度高的父代公式树 A,并从中随机选择节点和叶子进行替换。叶子 A2被其他叶子替换,并且某一节点 A1 上的公式被与其含有相同参数个数的公式所替换,以此形成后代
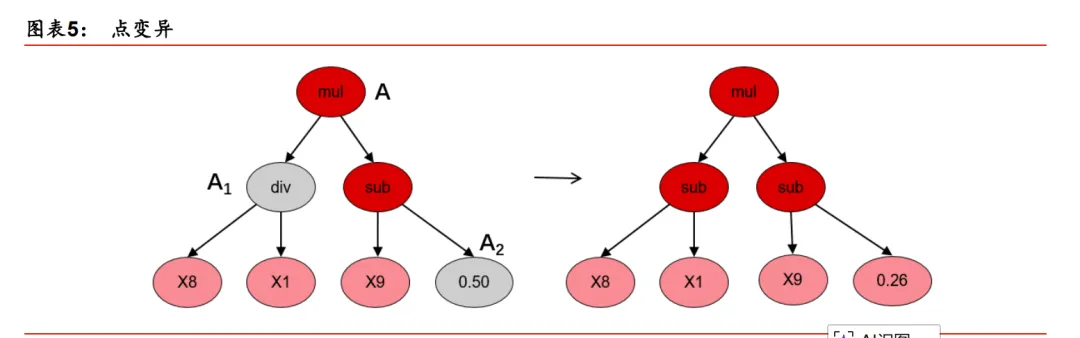
Hoist 变异
Hoist(提升)变异是一种对抗公式树过于复杂的方法。这种变异的目的是从公式树中移除部分叶子或者节点,以精简公式树。如图表 6 所示,Hoist 变异选取适应度高的父代公式树A 并从中随机选择子树 A1。然后从该子树中随机选取子树 A11,并将其“提升”到原来子树 A1 的位置,以此形成后代
gplearn 的简介和改进
gplearn 的简介和关键参数说明gplearn(https://gplearn.readthedocs.io)是目前最成熟的 Python 遗传规划项目之一。gplearn 提供类似于 scikit-learn 的调用方式,并通过设置多个参数来完成特定功能。图表7 展示了 gplearn 的主要参数

gplearn 的改进
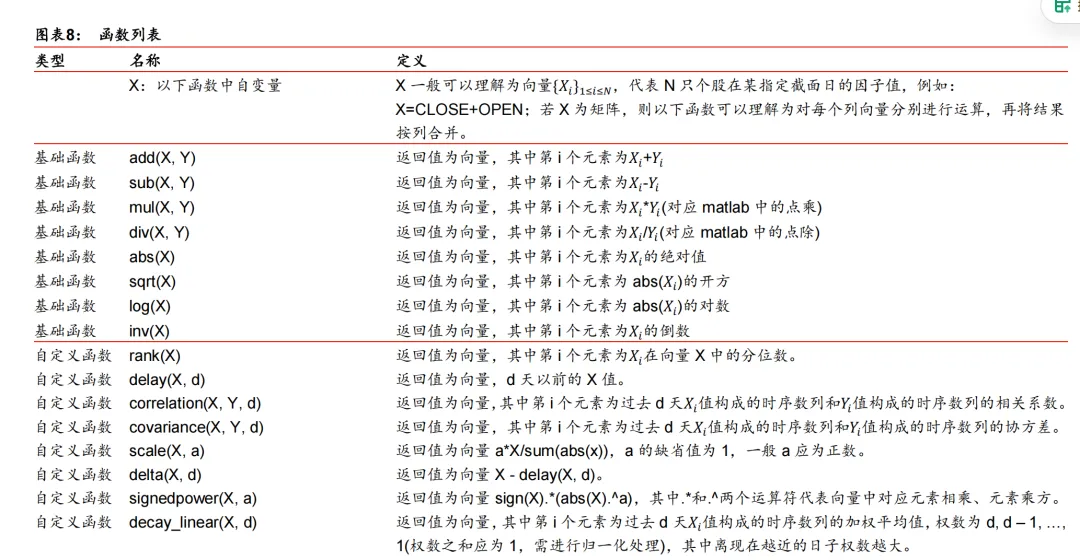
gplearn 提供了一套简洁、规范的遗传规划实现代码,但是不能直接运用于选股因子的挖掘。我们从源代码的层面,对 gplearn 进行了深度改进,使得其能运用于选股因子的挖掘。首先,我们扩充了 gplearn 的函数集(function_set),提供了更多特征计算方法,以提升其因子挖掘能力。除了 gplearn 提供的基础函数集(加、减、乘、除、开方、取对数、绝对值等),我们还自定义了一些函数(包括多种时间序列运算函数,这是 gplearn 不支持的),函数列表详细展示在图表 8 中。其次,我们改进了 gplearn 使得其能进行单因子测试。在测试过程中,还可以对待挖掘因子进行传统风格因子中性化。另外,遗传规划由于涉及到大量的随机操作,时间开销较大,我们还使用了 Python 中的并行运算技术,加快了因子矩阵的运算速度,缩短了因子挖掘时间

上面大概是我下面用简单的例子,代码来理解这个内容,代码只做学习参考
一、 市场逻辑与目标设定
观察到的现象:在A股市场中,有些股票在开盘后急速冲高,但随后动能衰竭,价格回落。这种“高开低走”或“冲高回落”的形态,可能意味着短期买盘力量耗尽,未来几天有回调压力。反之,那些“稳步推升”或“低开高走”的股票可能更具持续性。
传统人工因子的局限:研究员可能会设计 (开盘价 - 前收盘价) / 前收盘价 或 (最高价 - 开盘价) / 开盘价 等因子。但这些线性组合可能无法捕捉“衰竭”的非线性时序关系,例如:开盘后第一分钟冲高5% vs. 开盘后半小时缓慢爬升5%,其含义可能完全不同。
我们的目标:利用遗传规划,自动挖掘一个能刻画“日内价格路径动量衰竭程度”的因子,并预测股票未来3日的收益率。
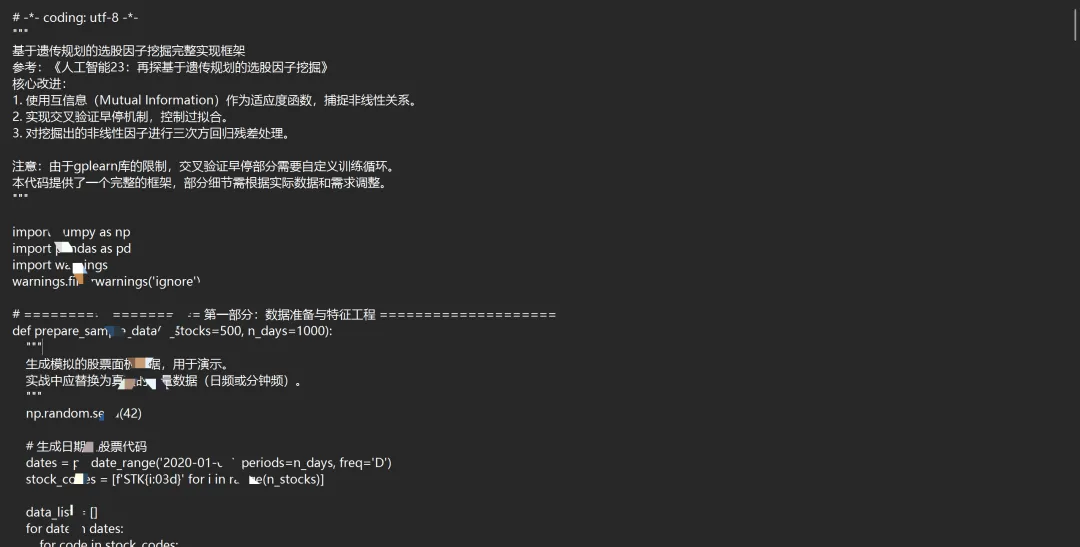
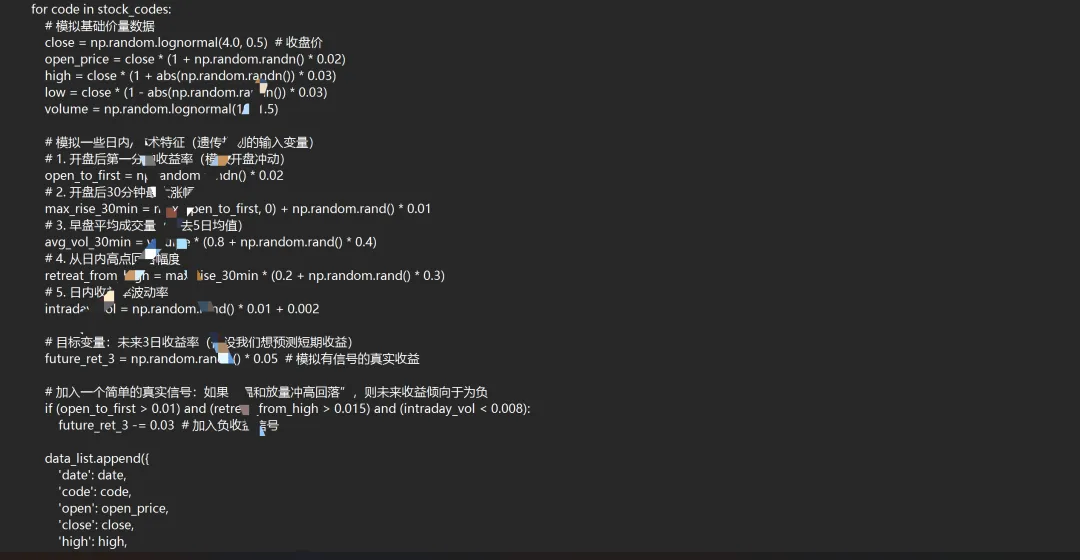
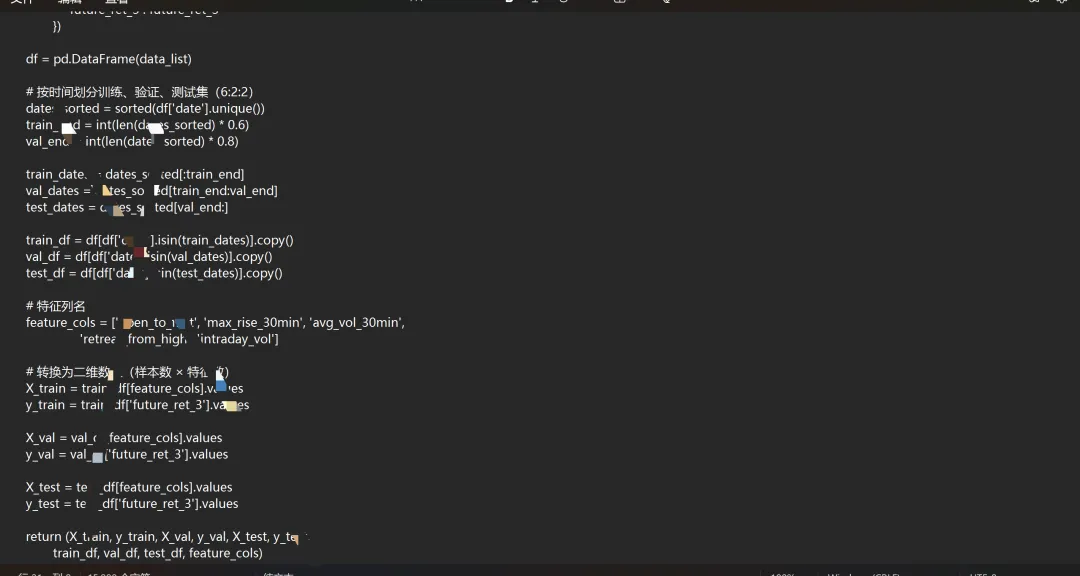
二、 数据准备与“基因”定义(代码实现)
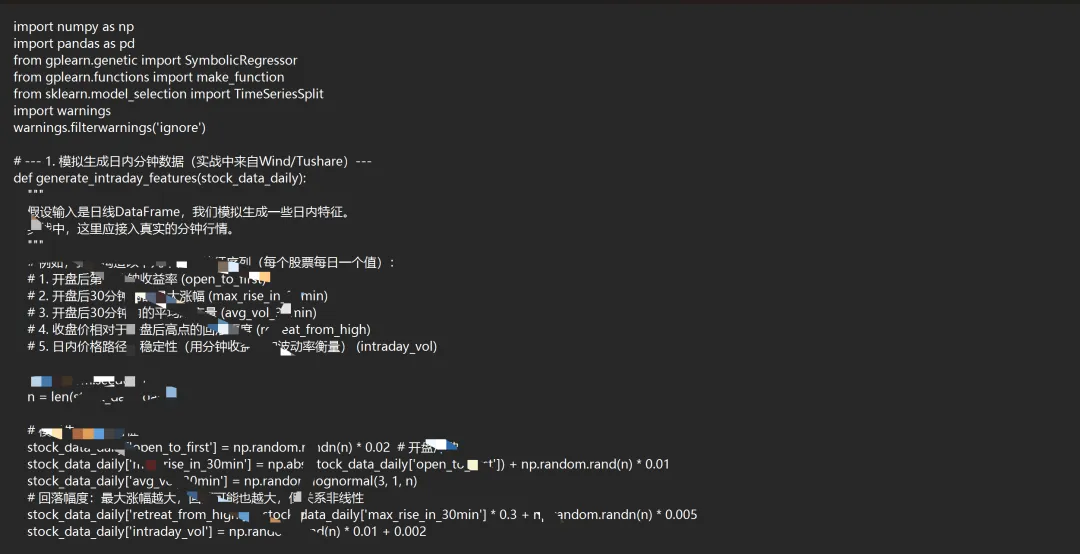
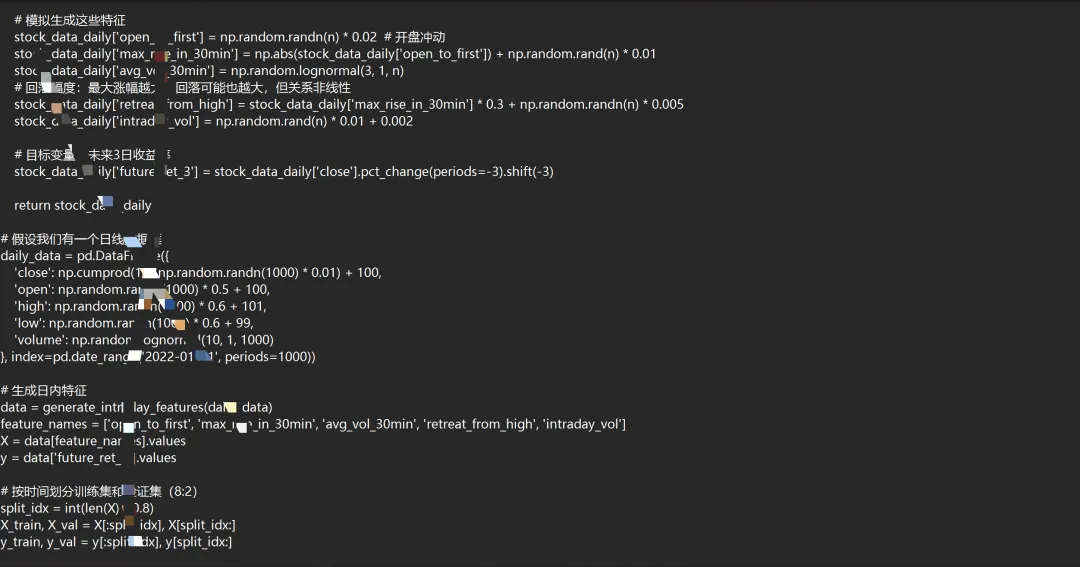
我们首先需要准备日内分钟级数据,并定义遗传规划可用的“零件”
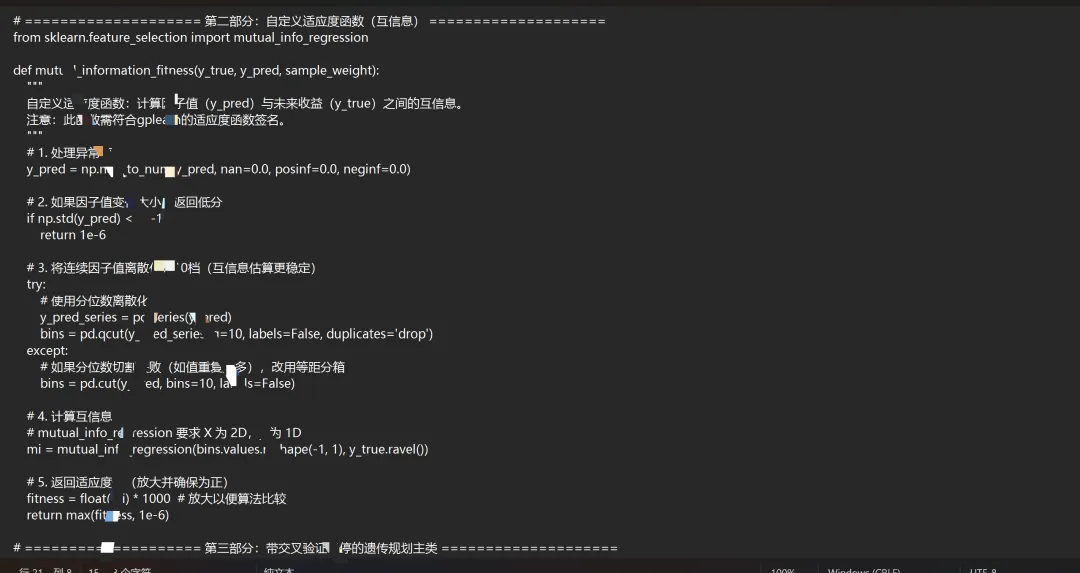
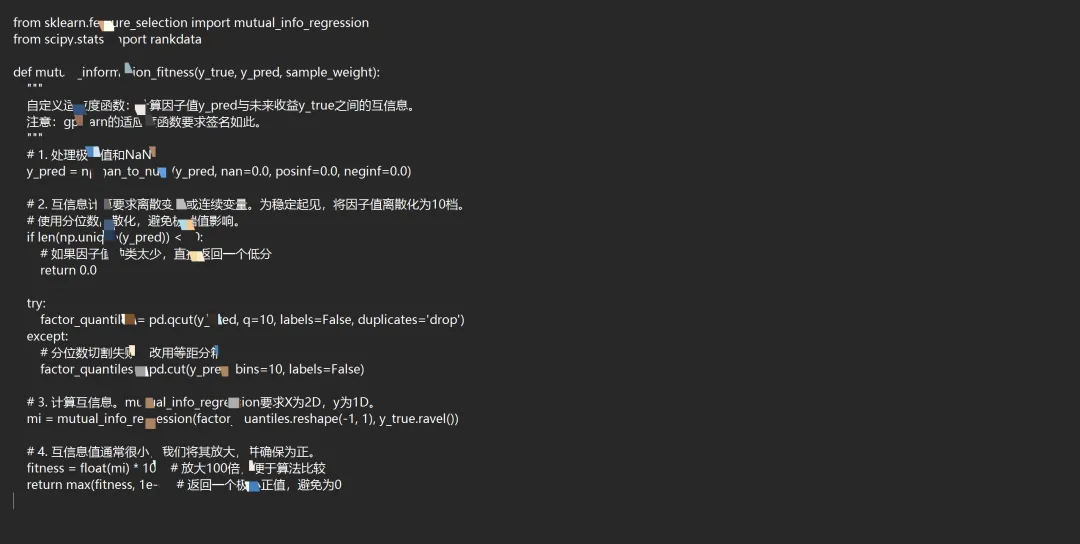
三、 关键改进1:定义新的适应度函数(互信息)
研报强调使用互信息(Mutual Information, MI) 替代线性IC。我们需要自定义适应度函数。
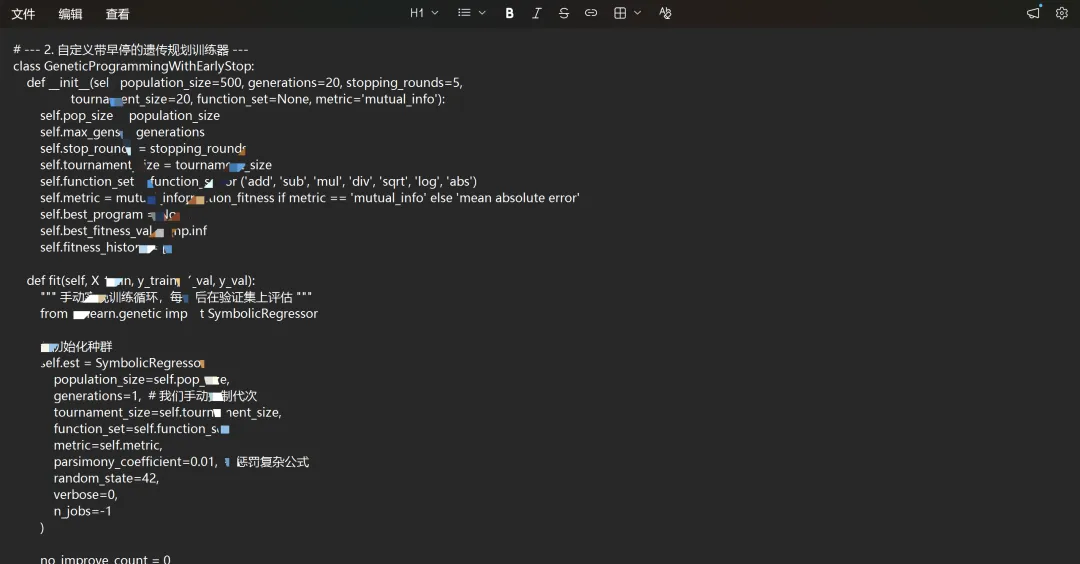
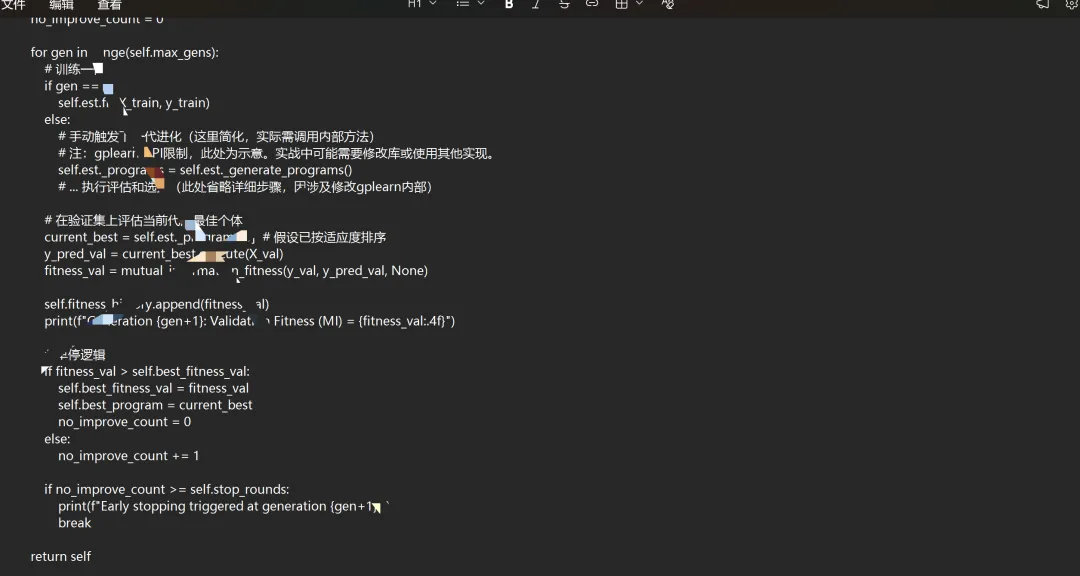
四、 关键改进2:实现带交叉验证的早停机制
标准gplearn不支持验证集早停。我们需要手动控制训练循环。
五、 运行遗传规划挖掘
现在,我们运行这个改进的遗传规划来挖掘因子
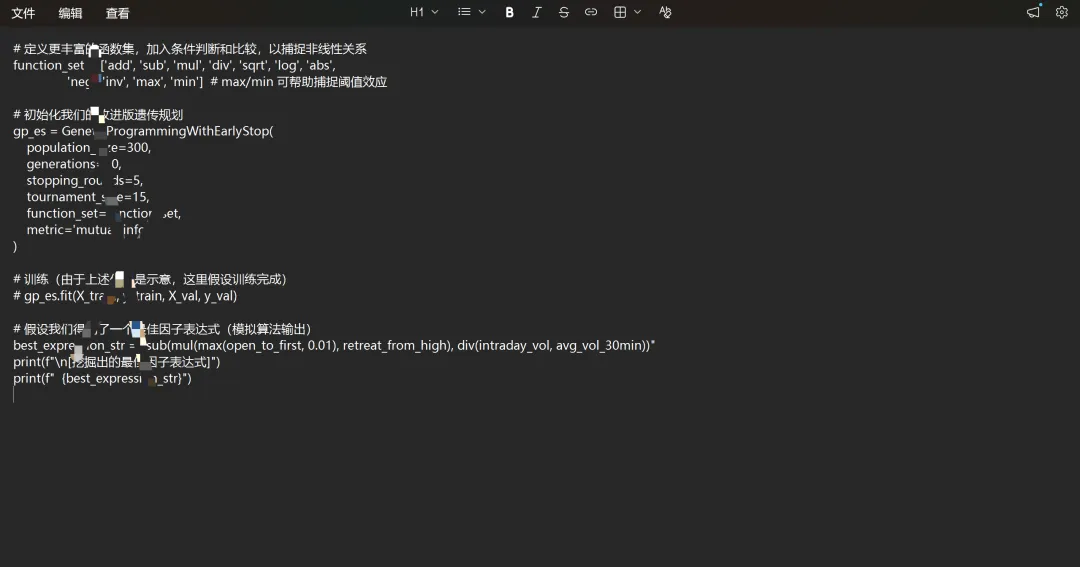
表达式解读:sub(mul(max(open_to_first, 0.01), retreat_from_high), div(intraday_vol, avg_vol_30min))翻译成数学公式:因子 = max(开盘第一分钟涨幅, 0.01) * 从高点回落幅度 - (日内波动率 / 早盘平均成交量)
逻辑分析:
max(开盘第一分钟涨幅, 0.01):非线性阈值处理。算法发现,只有当开盘冲高超过1%时,这个信号才有意义( max函数的作用)。小于1%的微小波动被忽略(设为0.01)。这是人工难以精准设定的阈值。* 回落幅度:将“冲高力度”与“回落幅度”相乘。这意味着冲得越高且回落越深的股票,该因子值越大(可能预示未来下跌压力大)。 - (日内波动率 / 早盘平均成交量):减去一个噪声项。算法发现,如果股票日内波动大但成交量小(即流动性差、价格跳跃大),这种“冲高回落”的可靠性会降低。因此,用这个比率来惩罚低流动性的高波动股票。
这个因子生动地刻画了“有量的冲高回落” vs “无量的价格抖动”的区别,其结构包含了非线性阈值(max)、交互作用(mul)和惩罚项(sub),远超简单的线性公式。
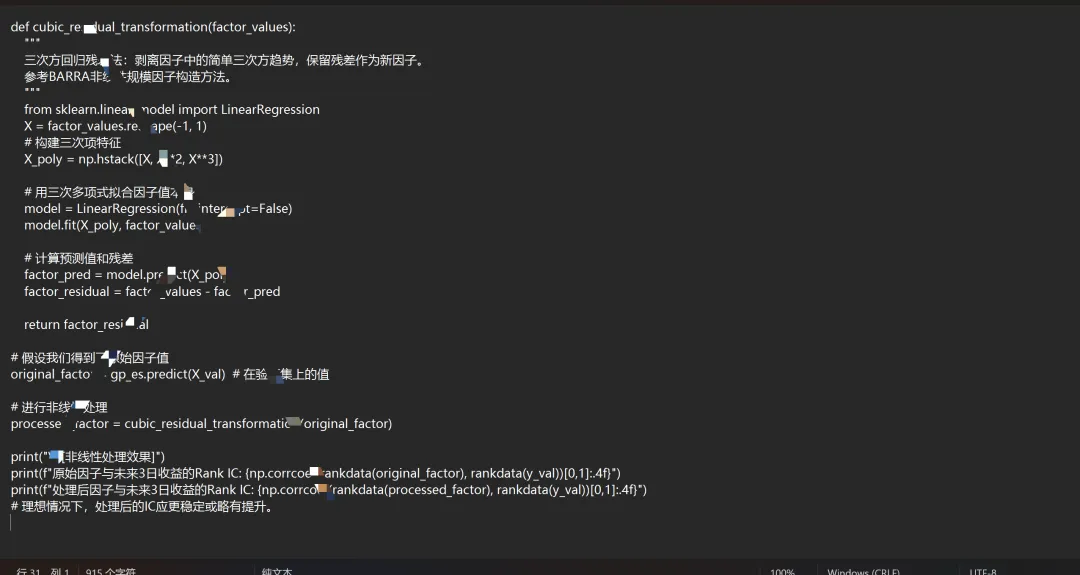
六、 关键改进3:非线性因子后处理
得到因子后,我们使用研报中的三次方回归残差法进行处理。
七、 样本外测试与策略构建
最后,我们在完全未参与训练和验证的样本外数据(例如,2023年的数据)上进行测试,并构建简单的策略。
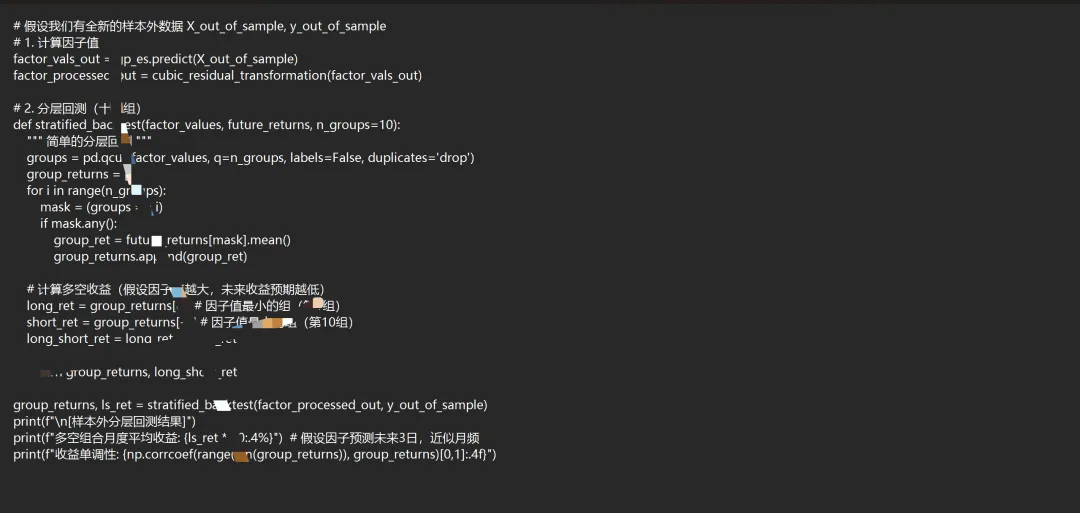
总结:代码如何体现研报核心思路
通过这个包含代码的详细例子,我们可以看到:
适应度函数的革新:我们抛弃了传统的'mean absolute error',实现了mutual_information_fitness函数。这使得算法在进化时,以最大化因子与收益间的非线性依赖关系为目标,从而能发现像max(open_to_first, 0.01)这样的阈值型非线性结构。
过拟合控制机制:我们设计了GeneticProgrammingWithEarlyStop类(尽管是示意),其核心思想是每代在独立验证集上评估,并实施早停。这直接对应研报中“在gplearn中引入交叉验证”的改进,确保挖掘出的因子具有泛化能力。
非线性因子处理:我们实现了cubic_residual_transformation函数。它将算法挖掘出的复杂因子(如包含max, mul, sub的表达式)进行数学变换,剥离其简单的三次方趋势,可能暴露出更稳健的Alpha信号。这是将“机器发现”的因子适配到传统线性多因子模型的关键一步。
完整的因子生产流水线:从数据准备(日内特征) -> 算法进化(带新适应度和早停) -> 因子解读(分析表达式逻辑) -> 后处理(三次方残差) -> 样本外验证(分层回测),形成了一套自动化、可解释、且严格控制过拟合的因子挖掘流程。
这个例子展示了,遗传规划不仅仅是一个“黑箱”优化器。在正确的框架设计(如研报提出的三项改进)下,它能成为一个强大的“公式发现助手”,从数据中自动提炼出符合金融逻辑、结构复杂但可解释、且经过严格风控检验的有效选股因子
目前我不能直接给大家提供代码,只能给思路参考,需要研报的找我就可以,加我进入量化专业服务群聊,不懂的问我就可以,技术支持
点赞加关注不迷路
下面截图一部分内容给大家参考思路
基于遗传规划的选股因子挖掘框架