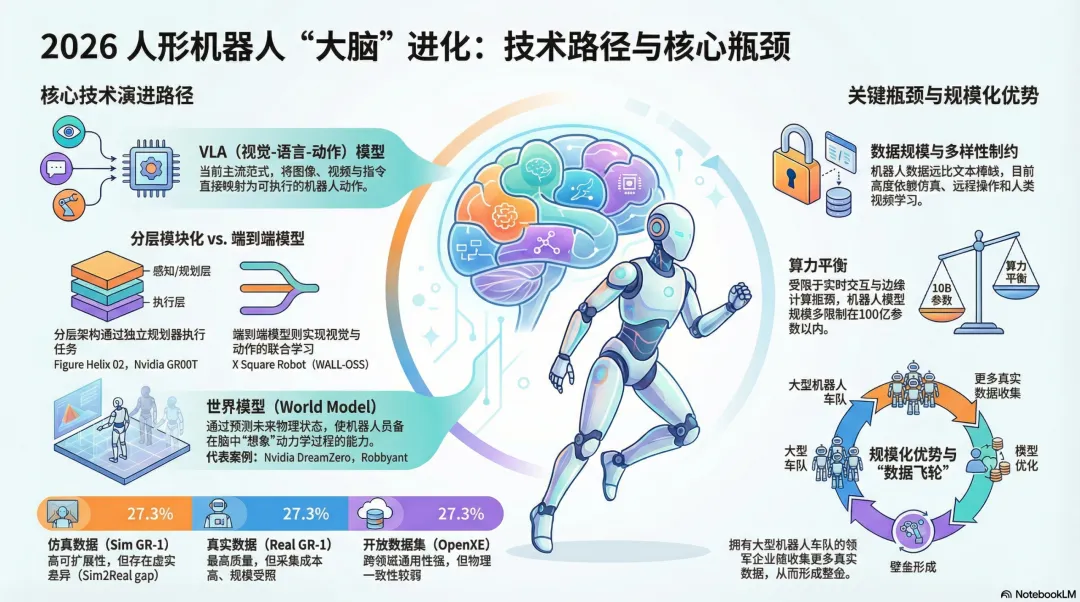
摩根士丹利研报-机器人“大脑”进化:技术路径与核心瓶颈人形机器人赛道最核心、却也最隐秘的战场——“大脑”,即机器人的控制与决策模型,随着硬件形态逐渐收敛,模型能力将成为2026年及未来最关键的差异化因素。不再是比拼谁先站起来走路,而是比拼谁的“脑子”更聪明、学得更快。目前,视觉-语言-行动VLA模型已成为绝对主流。简单说,就是让机器人能“看懂”(视觉)、“听懂”指令(语言),并“执行”动作。国内外主要玩家,从Figure、Physical Intelligence到国内的Galaxea、X Square Robot等,都采用了这一路径,其机器人已能完成特定任务。然而,通向通用机器人的道路布满荆棘。VLA模型面临四大现实挑战:物理属性理解不足:难以精确感知物体的硬度、重量、摩擦力。长任务规划困难:完成“泡一杯咖啡”这类需要多步骤组合的任务仍是难题。多样性应对乏力:面对没见过的物体、新环境或新任务,容易懵圈。响应延迟:从感知到行动的时间还不够快,影响实时交互。尽管有局限,短期內VLA仍将是中国公司的主攻方向,改进路径集中在:1)用更强的基座模型提升空间推理;2)加入“思维链”或推理模块;3)通过强化学习优化输出质量。与此同时,顶尖AI实验室和高校则在探索更激进的“世界模型”等新架构。例如英伟达的DreamZero,让机器人在“脑海”中模拟推演物理变化,再决策行动,在新任务泛化能力上表现出了显著优势。模型要变聪明,需要海量、高质量的数据来“喂养”,但机器人数据恰恰是稀缺资源。当前数据收集的三大痛点:远程操作:成本极高,需要熟练操作员和精密设备,难以规模化。仿真数据:量大但“仿真与现实差距”显著,精细的物理交互难以模拟。人类视频:虽然互联网视频取之不尽,但与机器人控制不对齐,缺乏深度、力反馈信息。提升仿真质量:用高质量仿真数据做预训练,减少对真实机器人数据的依赖。以英伟达Isaac Sim为代表,美国公司更侧重此路径。建设“数据工厂”:中国企业的重点打法。在政策支持下,建立大型机器人集群(100+台)和数据中心,执行标准化任务,实现数据生产的流水线作业。采集第一视角操作视频:用带摄像头的动作捕捉手套录制人类操作,成本低于操控整台机器人。有公司称其天津的工厂每日可生成9万条轨迹数据。利用“跨本体”数据:一个突破性进展是,最新模型证明,从不同机器人硬件上收集的数据可以混合使用,极大增加了高质量数据的可用性。算力是另一个较少被讨论但至关重要的约束。与大语言模型不同,机器人必须实时与物理世界交互,无法接受“思考几分钟”。因此,模型必须小而快,当前主流尺寸被限制在约100亿参数左右,远小于动辄千亿、万亿参数的LLM。报告指出,即便是英伟达最新的Thor芯片,其算力对许多公司的边缘计算需求而言仍显不足。人形机器人将是一场规模游戏,领先者与落后者之间的差距会随时间拉大。核心逻辑在于“数据飞轮”:部署规模越大的公司,能收集到越多、越多样化的真实世界数据;更多数据训练出更智能的模型;更智能的模型带来更好的机器人性能和更广泛的应用;这又进一步推动更大规模的部署,形成正向循环。同时,仿真预训练和世界模型的研发,也将高度依赖计算资源,进一步加强头部玩家的结构性优势。最终,行业可能向两种模式收敛:独立的模型提供商(类似机器人界的“安卓”系统,由科技巨头主导)。拥有庞大机器人舰队、能支撑快速模型迭代的全栈玩家。在脑力进化是场“持久战”的共识下,中国企业采取了更务实的策略:将机器人部署到大量具体场景中,在收集数据训练大脑的同时,并行迭代身体硬件。基于这种“小步快跑、逐步迭代”的路径,摩根士丹利在供应链中更看好组件供应商,看好谐波减速器领域的绿的谐波。在基础模型架构尚未统一、数据和算力存在瓶颈的阶段,能够提供稳定、高性能核心零部件的公司,其商业化和业绩增长的确定性相对更高。2026年人形机器人的竞争,数据是燃料,算力是引擎,模型架构是蓝图。这场竞赛没有捷径,唯有在真实场景中不断积累、迭代,才能最终孕育出真正智能的通用机器人。而在这个漫长进化过程中,供应链的“卖水人”或许将率先享受到行业增长的第一波红利。