野村研报-深度解析DeepSeek V4技术突破,中国AI产业链迎来价值重估2025年初,DeepSeek推出的V3与R1模型已让市场见识到“高效计算”的威力。一年后的今天,随着V4发布临近,两项突破性技术——mHC(流形约束超连接)和Engram(条件记忆模块)正引发新一轮产业思考。这份报告详细剖析了技术演进如何重构全球AI价值分配逻辑。一、回顾V3/R1:效率革命的开端
DeepSeek-V3采用6710亿参数规模的MoE架构,仅激活370亿参数即可实现对标国际一流模型的性能。其创新点包括:多头潜在注意力(MLA)机制,通过低秩压缩降低内存占用而R1推理模型更展示出纯强化学习实现复杂推理的潜力。这种“少即是多”的设计理念,使得中国AI应用开发成本显著降低,但并未削弱全球云服务商对算力的投入热情,反而刺激更高效的基建升级。二、V4核心技术突破:从连接到底层架构的重构
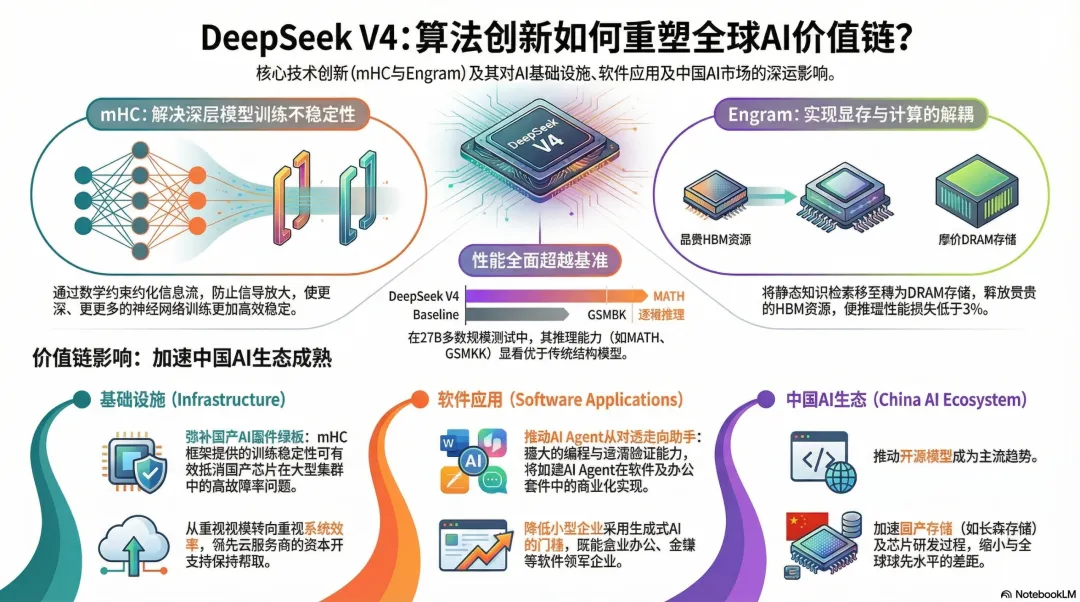
(1)mHC:解决深度学习根本性瓶颈
传统Transformer依赖的残差连接在千层级网络中已成为信息流动瓶颈。mHC通过三项创新实现突破:系统级优化更体现工程实力:内核融合将多个操作合并为单一CUDA内核,重计算技术动态管理内存,双管道调度优化通信延迟。在数学推理任务上,27B参数模型性能提升显著。(2)Engram:解耦计算与存储的新范式
该模块将静态知识检索(如实体、公式)与动态推理分离,形成异构架构:关键价值在于:训练阶段通过All-to-All通信实现线性扩展,推理时可将百亿级参数表卸载至CPU DRAM,HBM占用降低至可忽略的3%以内。三、产业链影响:中国AI的破局之路
硬件层:国内AI芯片企业迎来技术适配窗口期。mHC的稳定训练特性可弥补国产芯片集群训练中的容错短板,摩尔线程、壁仞科技等公司有望在优化算法支撑下提升市场接受度。应用层:AI智能体正从对话工具向任务执行助手演进。阿里“千问APP”已展示多步骤自动任务能力,金山办公、金蝶国际等软件厂商通过集成先进模型构建更强大功能套件。尽管存在“LLM取代软件”的担忧,但实际趋势是头部厂商通过AI增强其产品壁垒。数据验证:OpenRouter统计显示,DeepSeek模型在开源模型令牌使用量中占比仍达绝对优势,但2025年下半年随着更多竞争者加入,市场呈现碎片化趋势。这种“百花齐放”恰恰说明技术扩散正在加速应用创新。四、投资逻辑:关注价值传导路径
算力效率提升者:紫光股份(000938 CH)等服务器厂商受益于AI基建加速光通信关键环节:光迅科技(002281 CH)在高速光模块领域技术领先软件赋能受益方:金山办公(688111 CH)等企业通过AI增强产品矩阵值得注意的是,模型进步不仅不会降低算力总需求,反而因智能体频繁交互增加令牌消耗,带动计算需求螺旋式上升。结语:技术民主化进程中的价值重塑
DeepSeek-V4的意义超越单纯性能提升,其通过架构创新实现“芯片墙”“内存墙”的迂回突破。当国际大厂仍执着于算力军备竞赛时,这种“四两拨千斤”的技术路径正为中国AI产业开辟独特发展赛道。未来的竞争,将是算法效率、工程实现与生态建设的综合较量。