
做量化最怕的不是因子不赚钱,是活太多太慢。
研报翻完了,因子公式看懂了,然后呢?打开编辑器,开始搬砖。把公式翻译成可执行的代码——这一步就够头疼了。研报里的公式各写各的,字段名得去数据库里一个一个找对应,代码敲完还得对接 Alphalens 做因子检验验证有效性。好不容易跑完一轮,因子不行,改参数再来一轮,整个流程又走一遍。重复几次,大半天就没了。
问题出在哪?研报人读、字段人找、代码人敲、bug 人调、评价人跑——每一环都在重复造轮子。
那这些重复劳动,能不能交给机器来做?当然可以!DolphinDB Starfish 的研报分析与衍生因子模块,就是干这个的。
离可验证的因子,只差一篇 PDF 的距离
过去从研报到可运行的因子,中间隔着三座大山:写代码、调 bug、跑评价。现在研报分析与衍生因子模块可以将操作流程压缩到三步:
第一步,上传研报 PDF,一键解析。AI 自动把因子名称、公式、经济含义全部拎出来。原来自己翻 PDF 做标注至少半小时,现在几分钟完事。漏了的或者想补充的,手动加一下就行——自动解析打底,人工修正兜底。
第二步,选好数据源。勾选允许 AI 访问的数据表,剩下的全是 AI 的活。
第三步——这才是真正省时间的地方——AI 自己理解表结构、匹配字段、生成计算代码,放到真实环境试运行。跑通了直接调用 Alphalens 进行评价,跑崩了把报错丢回给模型自己修。修完再跑,跑崩再修,一直迭代到跑通为止。
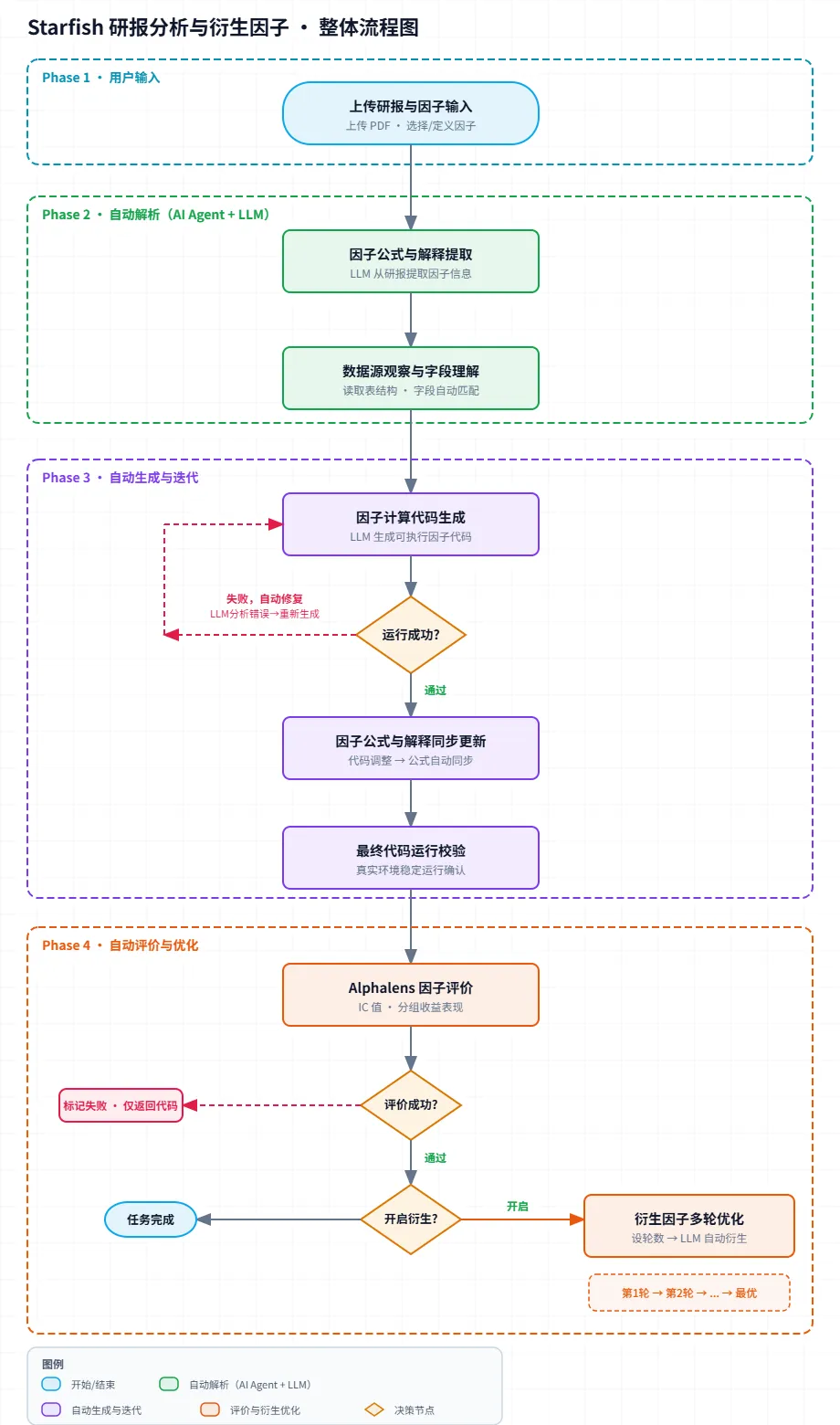
代码跑崩了?AI 自己修,研究者只管看结果
刚接触时也许会有这样的疑虑:“AI 写的代码肯定跑不通吧?真的可以信任 AI 给出的代码吗?”
答案是:跑崩了才正常,重点是它自己会修。
Starfish 平台的研报分析与衍生因子功能模块内置了一个自动迭代闭环:代码生成后立即执行,如果报错,系统把错误信息原封不动丢给大模型分析,模型分析完重新生成修复代码,再执行。如此反复,直到代码可运行为止。
更妙的是,在这个过程中,如果模型发现需要对公式本身做调整,它会同步更新因子的公式和解释说明,确保最终的计算逻辑和文档描述保持一致。
换句话说,从因子提取到代码运行再到结果评价,每一步 AI 都在自我校正。研究者不需要守在电脑前盯着终端输出,只需要在最后一步做出判断——这个因子逻辑对不对、要不要用。
更进一步:让 AI 帮你自动衍生优化
这是 Starfish 的衍生因子模块中最实用的功能之一。
如果用户手上有一个因子,想试试不同参数、不同处理方式能不能跑出更好的结果,放在过去用户得手动调、手动跑、手动记录对比。
而Starfish 的衍生因子模块让用户设个轮数,AI 会自动尝试标准化、平滑处理、参数调整等各种方向。每一轮基于上一轮的结果进行改进,逐轮生成因子、逐轮跑评价。所有轮次完成后,系统自动基于 IC 均值、方差等统计指标,直接告诉用户哪个版本最优,还带可视化对比。
原本一个人手工调参对比的效率,跟这个比,完全不是一个量级。
老团队也用得上:知识库加持,越用越聪明
如果团队之前已经积累了大量因子实现代码,Starfish 还支持接入知识库(RAG 检索增强生成)。
这意味着什么?AI 在生成因子代码或修复 bug 的时候,会先在知识库中检索相似因子或历史报错记录,把团队沉淀的最佳实践作为上下文喂给模型。用得越久,AI 的产出越贴合团队的风格。
对有历史积累的量化团队来说,这是一个隐形的加速器——知识库本身就是团队最值钱的数据资产,现在 AI 能直接为它所用。
权限管理,企业级部署无忧
对于团队管理者,Starfish 提供了细粒度的 AI 权限管控:
• 任务配额控制:限制单个用户可创建的研报因子和衍生因子任务数量,防止 AI 调用成本失控 • 数据源权限:精确到表级别,AI 仅可访问已授权的数据,防止模型误触大规模数据导致性能问题 • 用量监控:所有用户的 AI 使用情况一目了然
此外,部署完成后,用户还可以在 AI Chat 中自由选择底层模型(支持多种主流大模型),确保 AI 的产出质量符合团队要求。
从研报到因子,研发流程正在被重塑
以前一个人一天精耕细作搞 1-2 个因子算不错了。现在可以同时丢好几篇研报进去,让 AI 并行跑,研究者把精力腾出来做真正重要的事——判断因子逻辑合不合理、策略怎么设计。
从研报上传到因子提取,从自动代码生成到调用 Alphalens 进行因子评价,从多轮衍生优化到知识库增强——DolphinDB Starfish 把因子研发的全链条手工环节逐一自动化。
欢迎点击阅读原文获取 Starfish 白皮书,也可访问 DolphinDB 官网了解更多 Starfish 平台详情,或联系团队申请试用,体验 Starfish 的强大能力。
关于 DolphinDB
由智臾科技研发的高性能分布式时序数据库 DolphinDB,不仅支持海量数据的高效存储与查询,更开创性地提供功能完备的编程语言以支持复杂分析,以及高吞吐、低延时、开发便捷的流数据分析框架,是计算能力最强的数据库系统之一。目前,DolphinDB 已广泛服务于券商、基金、银行、保险等金融机构,以及能源、电力、工业制造等物联网行业的头部企业,显著提升了海量数据分析的效率,大幅降低开发成本。


扫码添加 DolphinDB 小助手,
往期 · 推荐

