

2026年4月19日,北京亦庄半程马拉松暨人形机器人半程马拉松开跑。和实验室里的单点演示不同,这一次机器人被放进了更长时程、更开放、干扰更多的真实环境中。如今机器人被检验的内容,不只是“能不能完成几个动作”,而是系统能否在连续执行中保持感知稳定、决策有效和动作可复现。

(北京亦庄半程马拉松暨人形机器人半程马拉松 图源:新华网)
这也体现了过去一年具身智能讨论的变化。行业关注点已经逐渐从“模型能不能做出效果”转向“系统能不能进入真实环境并稳定工作”。当机器人走出实验室,光照变化、物体摆放偏差、接触误差、环境干扰和长尾异常会使系统边界暴露。很多看起来像模型能力不足的问题,实际上都在于数据供给、数据处理和反馈闭环。
机器人要进入物理世界,不仅要“看见”,还要“理解”,更要“动手”并承担动作后果。相比互联网文本数据,具身智能数据天然更贵、更稀缺,也更难标准化。模型能否跨场景泛化、系统能否持续迭代、工程能否真正落地,最后都绕不开数据这一层。
作为北京大学学生人工智能创新会,我们持续跟踪具身智能前沿,围绕其核心技术体系与产业落地逻辑展开系统研究。具身智能系列报告将从 VLA、世界模型、数据、机器人硬件四个板块,对技术内核、关键瓶颈和产业前景进行拆解。
本次发布的研报聚焦数据板块。与大众理解中“数据就是训练材料”不同,在具身智能中,数据同时决定模型如何学习、系统如何部署、反馈如何回流,以及真实世界中的长尾问题如何被逐步吸收。换言之,数据不是附属资源,而是具身智能能否从实验室走向开放环境的关键变量。
本文为研报预览,完整深度分析、技术细节与行业研判,请在公众号后台回复【具身智能研报】。
一、为什么数据正在成为具身智能的关键变量
具身智能中的数据问题,和文本大模型处在不同层面。文本模型面对的是静态符号空间,而机器人面对的是连续、动态、受物理约束的真实世界。对机器人来说,一条数据往往同时包含视觉观测、语言指令、动作轨迹、状态反馈和环境变化,它记录的不是一个“答案”,而是一整条交互链路。
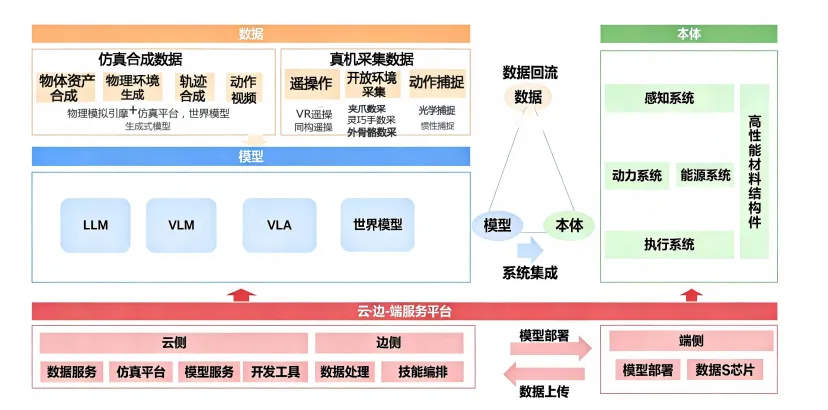
(图源:中国信息通信研究院)
也正因为如此,数据在具身智能中至少承担了三类作用。
第一,它支撑动作决策学习。以 VLA 模型为例,模型需要从视觉和语言输入中学习“当前该做什么”,因此对数据的要求不是简单“量大”,而是视觉、语言、动作之间必须高度对齐,且要覆盖足够多的任务变化、失败样本和异常场景。
第二,它支撑环境建模。世界模型更关心环境如何演化、动作会带来什么后果,因此更依赖连续时序、物体属性、接触关系和反馈结果。没有真实数据提供的物理锚点,模型就很容易只学到统计相关性,而难以形成稳定的场景推演能力。
第三,它决定系统能否形成闭环。具身智能里的数据并不是“采完就结束”。传感器和硬件决定了能观测到什么,模型训练暴露出哪些薄弱场景,执行中的失败轨迹又会反过来定义下一轮数据采集重点。真正有价值的数据体系,最终会形成“采集—处理—训练—反馈—再采集”的持续迭代机制。
也正因为如此,具身智能当前的瓶颈,往往不是“缺模型”,而是缺少能支撑训练、部署和回流的高价值数据。
二、具身智能真正需要什么数据
如果说“能采到数据”只是起点,那么“什么样的数据才真正有用”才是更关键的问题。
和传统视觉任务相比,具身智能数据有几个鲜明特征。首先是多模态强耦合。视觉、语言、动作、位姿、力觉和环境状态并不是并列存在,而是共同构成一次完整交互。其次是强时序因果性,数据必须保留“动作执行—环境反馈—策略调整”的链条,否则模型很难学到稳定规律。再往后是高成本与高稀缺性,以及强场景依赖性:同一个任务放到不同光照、材质、空间布局或干扰条件下,数据分布都会显著变化。
这意味着,具身智能里的“好数据”不能只看清晰度或标注精度,而必须同时满足三个条件。
一是基础质量过关。数据要真实、完整、内部一致,关键时序链条不能断,多模态之间不能彼此矛盾。
二是与模型目标匹配。VLA 模型更依赖视觉—语言—动作对齐数据,世界模型更依赖连续时序、状态反馈和动作后果数据。高质量数据如果不对应训练目标,价值会明显折损。
三是工程上可用。数据要有统一格式、清晰元数据、较低的二次清洗成本,还要能够进入后续训练、评估、回流和版本管理流程。很多数据“看起来不错”,但一旦进入真实工程链路就无法复用,这类数据很难转化成系统能力。
从这个角度看,具身智能稀缺的从来都不只是“数据量”,而是结构合理、目标明确、可进入闭环的高价值数据。
三、行业现在怎么组织数据
如果把视角转向行业实践,可以看到头部厂商的分化并不只是产品路线不同,背后更关键的差异在于“如何组织数据供给”。
目前较常见的路径大致有几类。
一类是真实世界持续回流型。它以真机数据为核心,在真实任务执行中不断采集、回流并迭代优化模型。这类路径最贴近实际部署,但成本高、扩张慢,对工程体系要求也最高。
一类是仿真扩样、真机校准型。它先借助高保真仿真环境快速生成大规模样本,再用少量真机数据做校准。优势是效率高、覆盖广,但最终效果高度依赖仿真和现实之间的偏差能否被修正。
还有一类更强调高精度动作与动力学积累,优先解决机器人“能不能稳定动起来”;另一类则围绕视觉—语言—动作统一建模,重点建设多模态同步数据底座;在医疗、康复、仓储、工业等垂直场景中,则更常见行业专属数据沉淀路径。
从这些实践里,可以提炼出几个相对明确的行业趋势。
首先,真实数据与仿真数据协同使用,已经成为行业共识。真实数据提供物理一致性,仿真数据提供规模和长尾覆盖,未来的竞争重点不是二选一,而是如何把两者组织成高效的数据结构。
其次,行业正在从“采样本”走向“建闭环”。真正有竞争力的数据体系,不再只是把样本交给训练,而是能根据训练反馈识别薄弱场景、失败模式和边界任务,再反向补充数据。
再次,高价值样本的重要性正在上升。随着数据总量增加,单纯堆规模的边际收益变小,失败轨迹、复杂接触、异常扰动和长尾任务等高信息密度样本,正在变得更关键。
最后,数据建设越来越场景化。通用数据仍然重要,但工业、物流、家居和医疗对关键数据的定义并不相同,真正决定落地效果的往往是与任务强绑定的数据体系。
四、为什么数据常常“采到了但没用好”
具身智能里一个常见误区是:只要采到了足够多的数据,模型能力自然会提升。现实并非如此。很多数据价值的流失,恰恰发生在采集之后。
一方面,原始多模态数据必须经过去重、降噪、格式统一、多模态对齐和异常剔除,才能转化为真正可训练的样本。只要这一流程中的某个环节出问题,后续训练就会迅速放大偏差。对于具身智能来说,采集阶段的轻微失控,往往会在预处理和训练阶段被成倍放大。
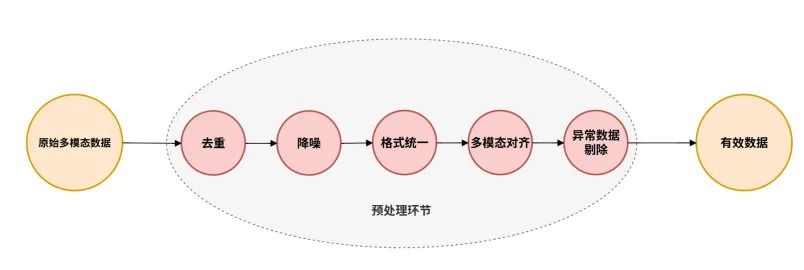
(图源:自主绘制)
另一方面,数据与模型的关系并不是“前者供给、后者消费”的一次性关系。以 VLA 模型为例,数据筛选需要兼顾成功轨迹与失败轨迹,还要围绕指令理解、动作映射和真实部署适配不断迭代。对世界模型而言,关键则在于能否提供足够充分的动作—后果数据、边界样本和失败样本,用真实数据持续校准其物理推演能力。
更进一步地说,数据的工程价值还取决于团队协同。数据团队、模型团队和硬件团队在目标、流程、格式和反馈节奏上天然不同,若缺乏统一元数据、统一接口和统一质控标准,协同成本会迅速抬高,大量已采数据也难以真正复用。
这也是为什么行业里常见的痛点,并不只是“真实数据不足”,还包括:仿真到现实偏差长期存在,多模态数据对齐和标准化困难,反馈链路过长、数据补充滞后 ,跨团队协同成本高、数据复用率低
换言之,很多时候限制系统进步的,不是没有数据,而是“好数据没有被真正用好”。
五、接下来行业要看什么
如果从更长的时间尺度看,具身智能的数据竞争将越来越不像“资源竞争”,而更像“基础设施竞争”。
未来值得重点观察的方向,至少有四个。
第一,采集与处理自动化。行业正在从高人工参与的数据链路,逐步转向自动化采集、自动化对齐、自动化标注和自动化质控。谁能更稳定地把原始样本转化为训练资产,谁就更有优势。
第二,真实、仿真与合成数据的混合供给。真实数据提供锚点,仿真数据扩规模,合成数据补长尾,这种混合结构很可能成为未来高质量数据底座的主流形态。
第三,标准化数据集与评测体系。行业如果长期缺乏统一的数据格式、场景划分和评测指标,不同团队之间的数据就很难复用,模型性能也难以真正对齐比较。
第四,安全与合规能力。具身智能数据往往涉及人脸、空间结构、工业流程和操作轨迹,未来规模化流通的前提,不只是“有没有数据”,而是“数据能否在安全合规前提下长期稳定使用”。

(图源:https://x-humanoid-robomind.github.io/)
综合来看,具身智能的长期竞争,不只是模型能力竞争,也不是单纯的硬件能力竞争,而是围绕高价值数据的获取、组织、训练和反馈回流展开的系统能力竞争。
谁能持续获得高价值数据,谁能把这些数据组织成可训练、可迭代、可复用的资产,谁就更有可能在下一阶段的具身智能竞争中占据主动。数据问题,短期看是训练问题,长期看是基础设施问题。

北大学生人工智能创新会,简称PKU SAIIC,是北大校内唯一的人工智能社团,由校团委,计算机学院团委、人工智能创新中心共同领导,施柏鑫老师指导。
研报作者:陈兆坤,王昕怡,Valeri
系列研报发起与统筹:Valeri
研报顾问:王思涵、余振葳
审核:施老师、于老师、Valeri、王鹏翔
排版:陈顺汶

