
为什么金融研报生成需要多Agent架构?
传统金融研报的撰写是一个高度知识密集型的工作流:分析师需要采集海量数据、解读财务报表、分析行业趋势、构建估值模型、撰写研报正文并通过合规审查。一份标准的深度研报通常需要1-2周的工作量,而卖方机构每年需要产出数千篇研报以覆盖其研究领域。
单一LLM难以胜任全流程:它既缺乏实时数据访问能力,也无法在一次对话中可靠地完成涉及多个专业领域的长链推理任务。多Agent系统的核心价值在于将复杂任务分解为多个专业化子任务,每个Agent专注于自己最擅长的领域,通过编排器(Orchestrator)协调工作,最终汇聚为一份完整的研报。
六大Agent的分工与职责是什么?
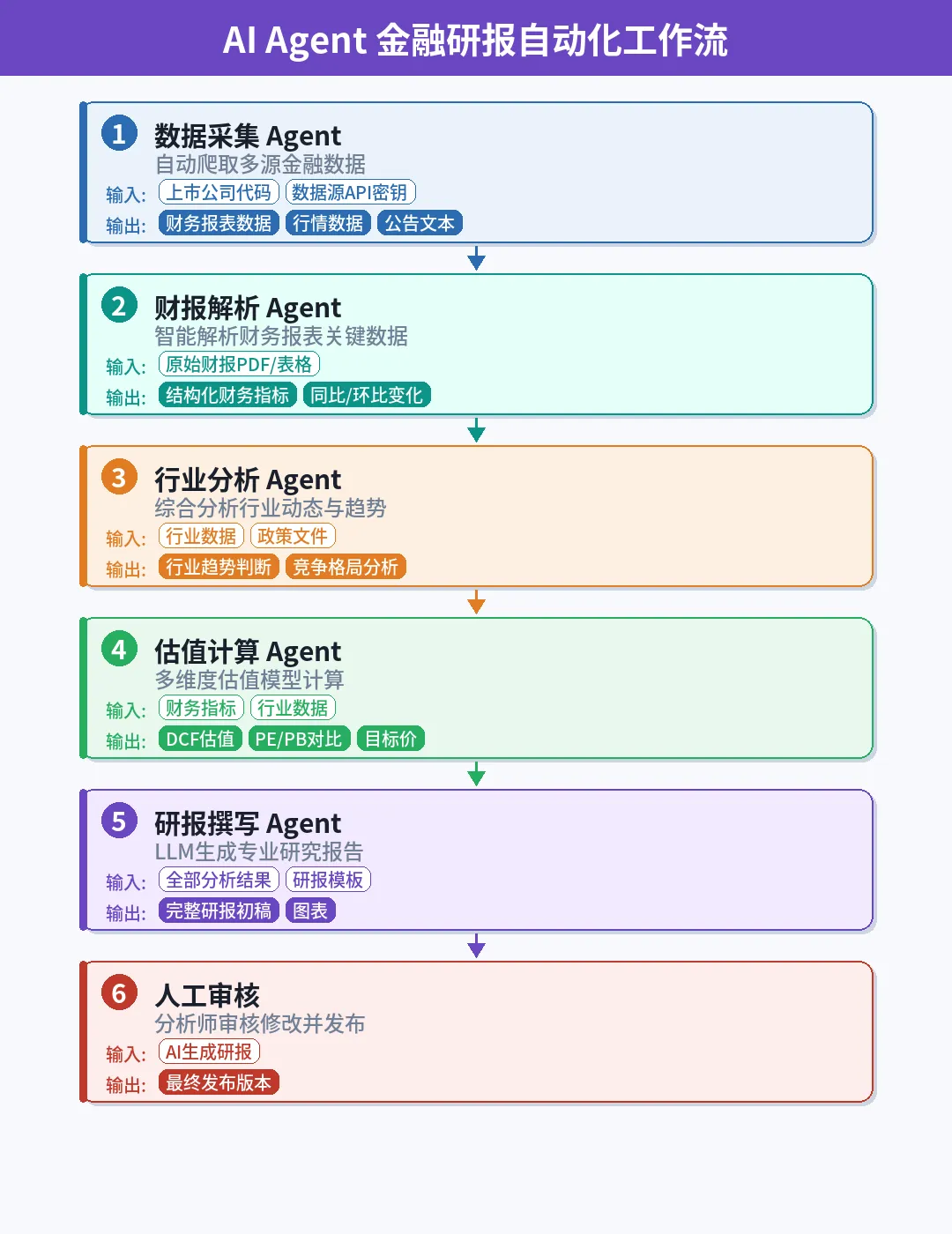
图:AI Agent金融研报全流程工作流
一个完整的AI Agent金融研报系统包含以下六个核心Agent:
Agent 1:数据采集Agent(Data Collector)——负责从多个数据源实时获取结构化和非结构化数据。数据源包括:Wind/Bloomberg API获取行情和财务数据、证监会/交易所公告系统获取监管信息、新闻聚合API获取市场动态、社交媒体API获取市场情绪信号。该Agent需要处理数据缺失、格式不一致和API限频等实际工程挑战。
Agent 2:财务解析Agent(Financial Parser)——对目标公司的财务报表进行深度解析。核心任务包括:三表(利润表、资产负债表、现金流量表)的自动化阅读和关键指标提取、同比/环比变化分析、财务异常检测(如应收账款异常增长、存货周转率骤降)。该Agent需要领域特定的微调或Few-Shot Prompting以确保财务数据解读的准确性。
Agent 3:行业分析Agent(Industry Analyst)——执行宏观经济和行业层面的分析。包括行业生命周期定位、竞争格局分析(波特五力模型)、政策影响评估、产业链上下游关系梳理。该Agent通常需要接入行业数据库和政策文件库。
Agent 4:估值建模Agent(Valuation Modeler)——构建定量估值模型。支持的估值方法包括DCF(自由现金流折现)、可比公司法(PE/PB/EV-EBITDA)、DDM(股利折现模型)。该Agent需要根据公司特征自动选择最合适的估值方法,并处理参数不确定性(如折现率的敏感性分析)。
Agent 5:报告撰写Agent(Report Writer)——将前四个Agent的输出整合为结构化的研报正文。关键能力包括:专业金融术语的恰当使用、投资逻辑的连贯阐述、风险提示的全面覆盖、以及符合特定研报模板的格式化输出。
Agent 6:质量审查Agent(QA Reviewer)——对生成的研报进行多维度质量检查。包括:事实核查(数据引用是否准确)、逻辑一致性验证(结论是否与论据匹配)、合规审查(是否包含不当表述或未披露的利益冲突声明)、以及可读性评估。
编排器架构如何保证各Agent的有效协同?
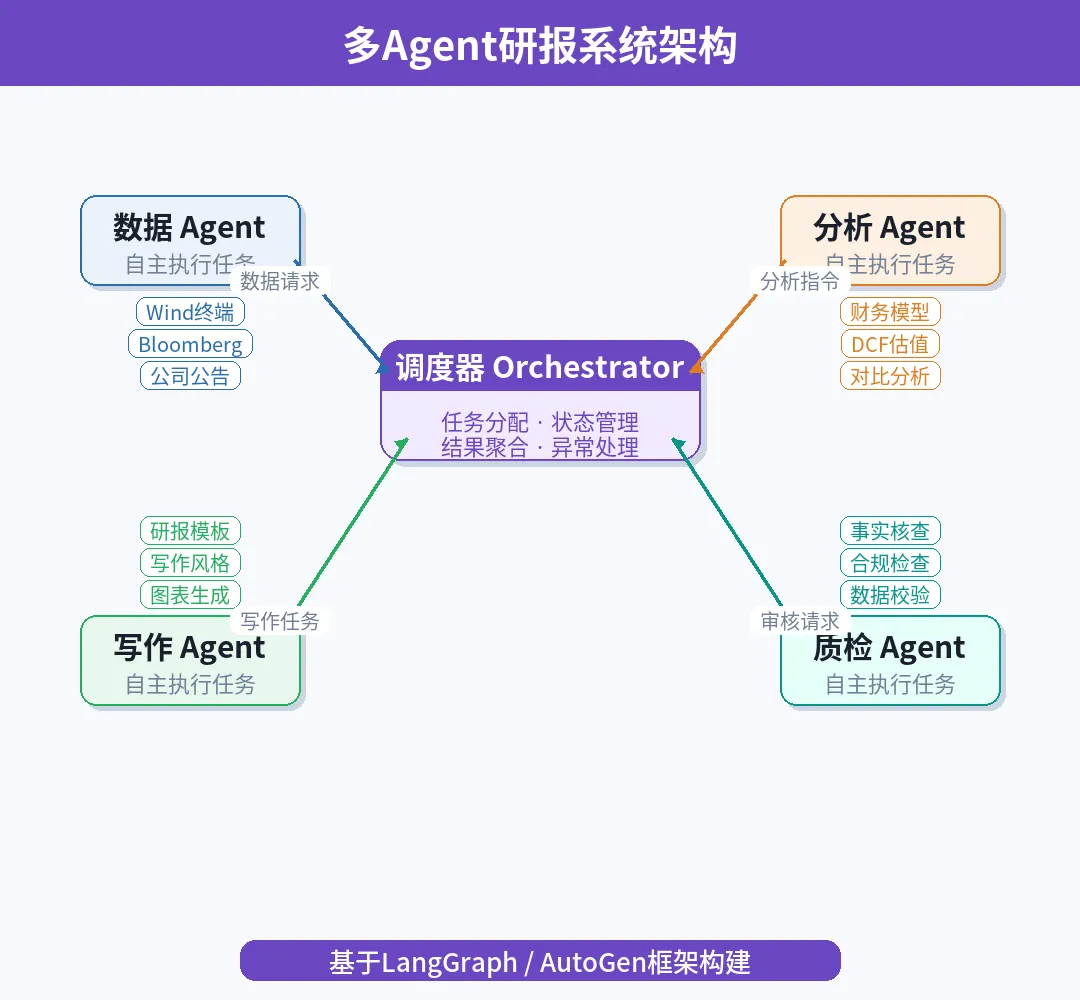
图:多Agent编排器架构设计
编排器(Orchestrator)是整个系统的“大脑”,负责任务分配、进度管理、信息传递和异常处理。推荐的架构设计采用分层调度模式:
第一层:任务规划层。接收用户输入(如“生成贵州茅台的深度研报”),自动分解为子任务并确定各Agent的执行顺序和依赖关系。数据采集和财务解析可以并行执行,行业分析和估值建模需要等待数据就绪。
第二层:执行监控层。跟踪每个Agent的执行状态,处理超时、失败和重试逻辑。关键设计原则是“快速失败”——当某个Agent的输出质量低于阈值时,立即触发重新生成而非将低质量输出传递给下游Agent。
第三层:结果汇聚层。收集所有Agent的输出,解决可能的信息冲突(如不同数据源给出的营收数据不一致),生成统一的上下文供报告撰写Agent使用。
技术实现方案如何选型?

图:主流Multi-Agent框架对比
当前主流的Multi-Agent实现框架包括LangChain/LangGraph、AutoGen和CrewAI,三者各有侧重:
LangChain/LangGraph:适合需要精细控制工作流的场景。LangGraph提供的图状态机能够精确定义Agent之间的信息流转路径和条件分支。推荐在需要复杂编排逻辑的生产环境中使用。
AutoGen(Microsoft):强调Agent之间的对话式协作,适合需要多轮讨论和迭代优化的场景。在金融研报生成中,可用于估值Agent和行业分析Agent之间的交叉验证对话。
CrewAI:提供了最简洁的API设计,适合快速原型开发。对于概念验证(PoC)阶段的金融研报系统,CrewAI可以在最短时间内搭建可运行的演示版本。
数据源接入方面,推荐使用tushare Pro或akshare获取A股数据,配合OpenAI/Anthropic的Function Calling能力实现工具调用。对于财务报表解析,可结合PDF解析工具(如MinerU)和结构化数据API实现双重验证。
Human-in-the-Loop机制为什么不可或缺?
在金融研报这样的高风险信息产品中,完全自动化是不负责任且不现实的。Human-in-the-Loop(人机协同)机制需要设置在以下关键节点:
第一,估值假设审查。折现率、增长率等关键假设必须由分析师确认,微小的参数变化可能导致目标价差异超过30%。第二,投资评级决策。买入/持有/卖出的最终评级涉及重大合规和声誉风险,应由资深分析师做出。第三,敏感信息过滤。自动化系统可能无意中引用内幕信息或未公开数据,需要合规团队的专业把关。
当前的技术局限与未来方向是什么?
坦率地说,当前的AI Agent金融研报系统仍面临多个技术挑战:
局限一:数据时效性。LLM的训练数据存在时间滞后,实时数据需要通过工具调用获取,但API调用的稳定性和数据质量难以保证。
局限二:数值推理能力。当前LLM在复杂的财务建模和数值计算方面仍然不够可靠,DCF模型中的多步计算尤其容易出错。建议将数值计算部分委托给Python代码执行而非让LLM直接推理。
局限三:长文档一致性。一份完整的深度研报通常超过20页,在如此长的文本中保持论述的一致性和连贯性仍然是LLM的薄弱环节。分段生成+全局审查的策略可以部分缓解这一问题。
展望未来,随着LLM推理能力的持续提升、金融专用模型的出现、以及Agent协作框架的成熟化,AI驱动的金融研报生成有望从“辅助工具”进化为“核心生产力”。但技术的进步不应削弱对专业判断和合规底线的重视——这是金融行业的根本原则,不会因为工具的变化而改变。


