影刀RPAPython解析东方财富研报Excel去重
朋友原本已经把东方财富个股研报页面的大部分采集做好了,表格里的文字信息基本都能拿到,但真正没处理好的有两个点:重复抓取和翻到下一页后的连续采集。我没有继续在原流程上堆复杂判断,而是直接按自己的思路重新整理了一版,让流程更短、逻辑更清楚、结果也更适合后续沉淀。
这次优化,核心解决了三件事
1)把页面一行原始 HTML 交给 Python 解析,不只拿文字,还把股票代码链接、详细链接、股吧链接、研报链接、机构链接、行业链接一起拆出来。
2)新结果会和当前 Excel 历史数据做比对,已存在就跳过,不再重复写入。
3)流程里把翻页逻辑也重新梳理进去,避免只停留在当前页面,保证可以持续往后抓。
1 为什么这样改
这个项目真正有价值的,不是单纯把表格文字抄下来,而是把字段背后的入口关系一起保留下来。像股票代码、详细、股吧、研报标题、机构、行业这些位置,本质上都是可点击入口。只抓文本,后续就没办法继续追踪详情页,也很难形成自己的研究资料库。
我这里的做法比较干脆:先获取当前行的原始 tr 代码,再交给 Python 统一解析。这样不仅字段更完整,而且后期加字段、改结构、适配别的网页时,维护成本也会低很多。
重复问题则直接放到结果层处理:新抓到的数据先和 Excel 里的历史数据比对,再决定是否写入。这类做法很适合长期运行的自动化项目,因为它天然支持反复执行、定时执行和历史沉淀。
2 这套项目最终能干嘛
① 自动沉淀研报数据:每天抓取最新个股研报,形成自己的历史表。
② 保留详情入口:不仅保存文本,还保存股票代码链接、股吧链接、研报链接、机构链接、行业链接,方便继续深挖。
③ 避免重复写入:结果和 Excel 历史数据比对,已存在就跳过,流程多跑几次也不会把同一条反复写进去。
④ 支持翻页续抓:不是只采首屏,而是把后续页面一起纳入流程,形成可持续采集的完整链路。
这类能力不只适用于金融页面,本质上它解决的是一类常见网页自动化问题:表格采集 + 链接提取 + 分页处理 + 历史去重。所以这套思路也适合行业资讯、政策公告、招投标信息、供应商名单、运营后台列表、竞品情报等场景。
3 方案拆解
RPA 负责流程控制:打开页面、获取相似元素列表、循环每一行、调用 Python 模块、读取 Excel、判断是否存在、写入结果、控制翻页。
Python 负责结构化解析:接收单行 HTML,把里面的文本与链接拆成统一结果列表返回。
结果层负责去重:把新数据与 Excel 中已有结果比较,存在就跳过,不存在再落表。这样职责清晰,流程也更容易长期维护。
4 Python 部分
为了兼容公众号排版,下面的代码区采用逐行稳定展示的方式处理,复制到公众号编辑器后更不容易出现断行错位。完整代码如下:
eastmoney_report_row_parser.py
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from datetime import datetime
def normalize_url(href: str, base: str):
if not href:
return ""
href = str(href).strip()
if href.startswith("//"):
return "https:" + href
return urljoin(base, href)
def clean_value(v):
if v is None:
return ""
v = str(v).strip()
if v in ("[]", "[ ]", "{}", "null", "None"):
return ""
return v
def get_current_time_text():
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def parse_row_to_list(html_text, base_url="https://data.eastmoney.com"):
if not html_text:
return
html_text = str(html_text).strip()
if html_text in ("[]", "[ ]", ""):
return
soup = BeautifulSoup(html_text, "html.parser")
tr = soup.find("tr")
if not tr:
return
tds = tr.find_all("td", recursive=False)
if len(tds) < 15:
return
def td_text(td):
return clean_value(td.get_text(" ", strip=True))
def first_link(td):
a = td.find("a")
if not a:
return {"text": "", "url": ""}
return {
"text": clean_value(a.get_text(" ", strip=True)),
"url": clean_value(normalize_url(a.get("href", ""), base_url))
}
def link_by_text(td, target_text):
for a in td.find_all("a"):
if clean_value(a.get_text(" ", strip=True)) == target_text:
return clean_value(normalize_url(a.get("href", ""), base_url))
return ""
stock_code = first_link(tds[1])
stock_name = first_link(tds[2])
report = first_link(tds[4])
org = first_link(tds[7])
industry = first_link(tds[13])
detail_url = link_by_text(tds[3], "详细")
guba_url = link_by_text(tds[3], "股吧")
row = [
td_text(tds[0]), # 序号
stock_code["text"], # 股票代码
stock_code["url"], # 股票代码链接
stock_name["text"], # 股票名称
detail_url, # 详细链接
guba_url, # 股吧链接
report["text"], # 研报标题
report["url"], # 研报链接
td_text(tds[5]), # 上次评级
td_text(tds[6]), # 评级变动
org["text"], # 机构
org["url"], # 机构链接
td_text(tds[8]), # 评级
td_text(tds[11]), # EPS
td_text(tds[12]), # PE
industry["text"], # 行业
industry["url"], # 行业链接
get_current_time_text() # 时间
]
row = [clean_value(x) for x in row]
if not any(row):
return
required_indexes = [0, 1, 2, 3, 4, 5, 6, 7, 10, 11, 15, 16, 17]
for i in required_indexes:
if not row[i]:
return
return row
def main(args):
if isinstance(args, str):
html_text = args
base_url = "https://data.eastmoney.com"
elif isinstance(args, dict):
html_text = args.get("html", "")
base_url = args.get("base_url", "https://data.eastmoney.com")
else:
return
result = parse_row_to_list(html_text, base_url)
if not result:
return
return result
这段 Python 的作用很明确
它不是去控制浏览器,也不是去做翻页循环,而是专门负责把一整行 HTML 解析成结构化结果。这样 RPA 和 Python 的边界会非常清晰,后期改流程和改解析可以分开维护。
5 流程截图说明
下面这张图是实际执行流程图,不是代码截图。整体逻辑就是:打开 Excel、打开东方财富页面、获取相似元素列表、逐行调用 Python 解析、读取 Excel 历史数据、判断是否存在、写入结果,然后继续处理翻页。整个思路比原流程更短,也更稳定。
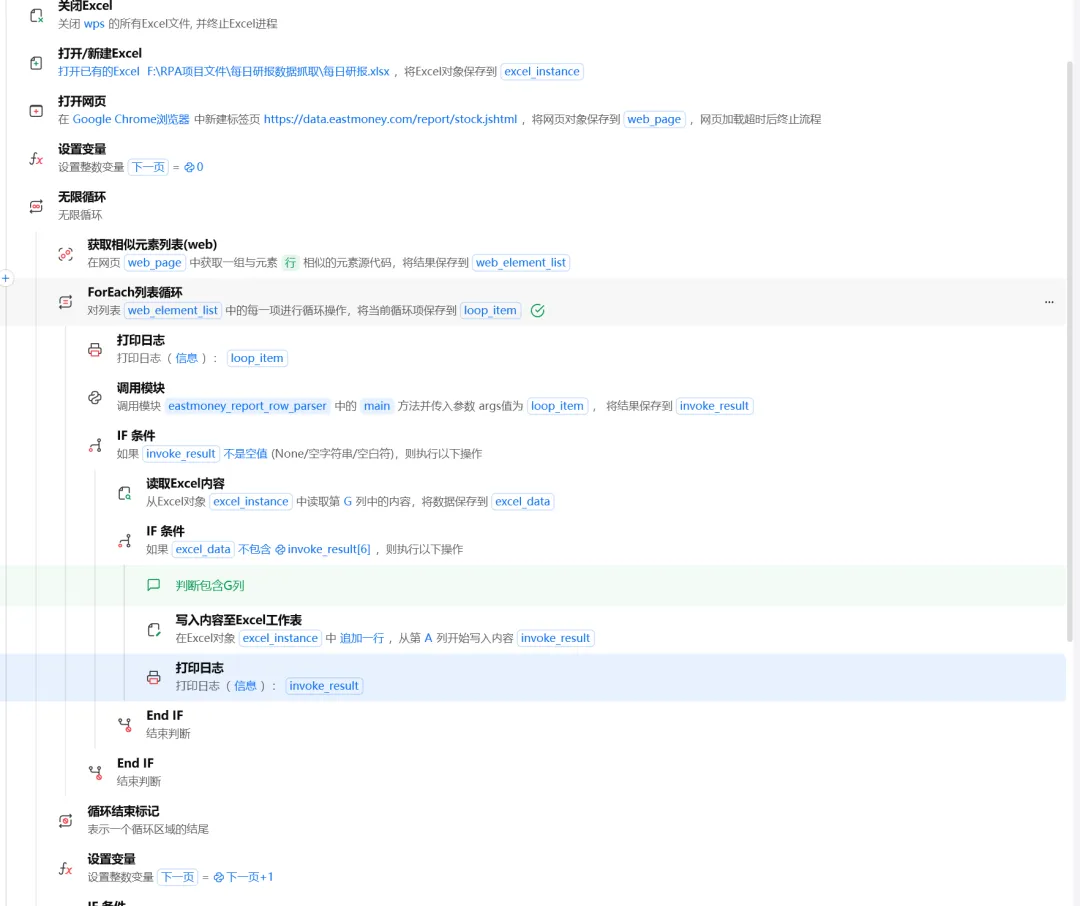
这里重点不是步骤多,而是职责拆分清楚:RPA 管流程,Python 管解析,Excel 管历史比对。
6 执行前后对比
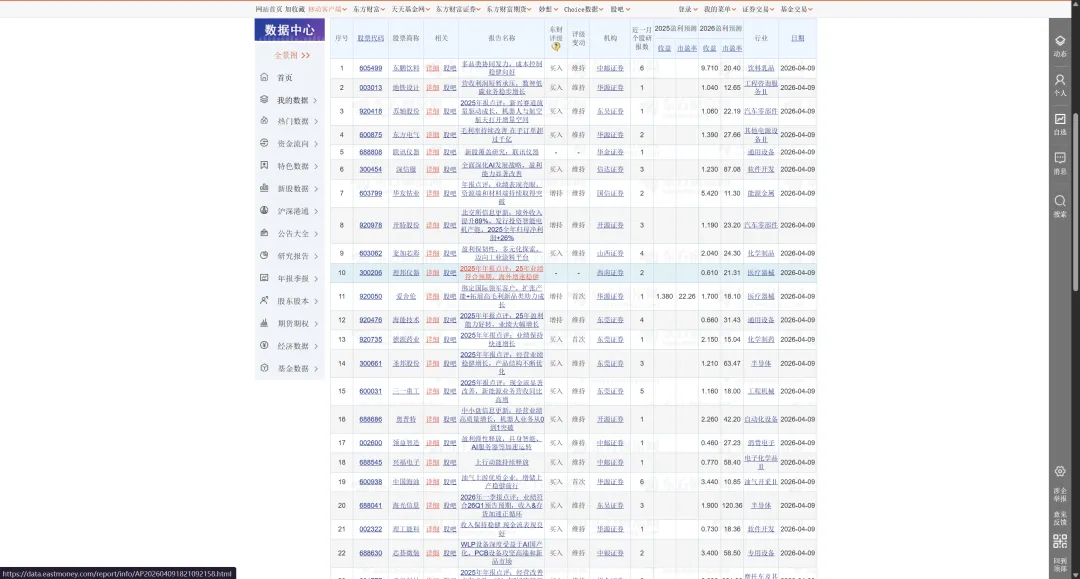
执行前,页面上看到的是一张普通列表表格,虽然股票代码、研报标题、机构、行业这些内容都能看见,但真正重要的是每个位置背后挂着的链接关系。如果只抓文本,结果只是“能看”,但不够“能用”。
执行后,Excel 中不仅有文本字段,还把股票代码链接、详细链接、股吧链接、研报链接、机构链接、行业链接都单独保留下来了。这样后续无论是继续打开详情、做历史对比,还是做筛选统计,都会顺手很多。
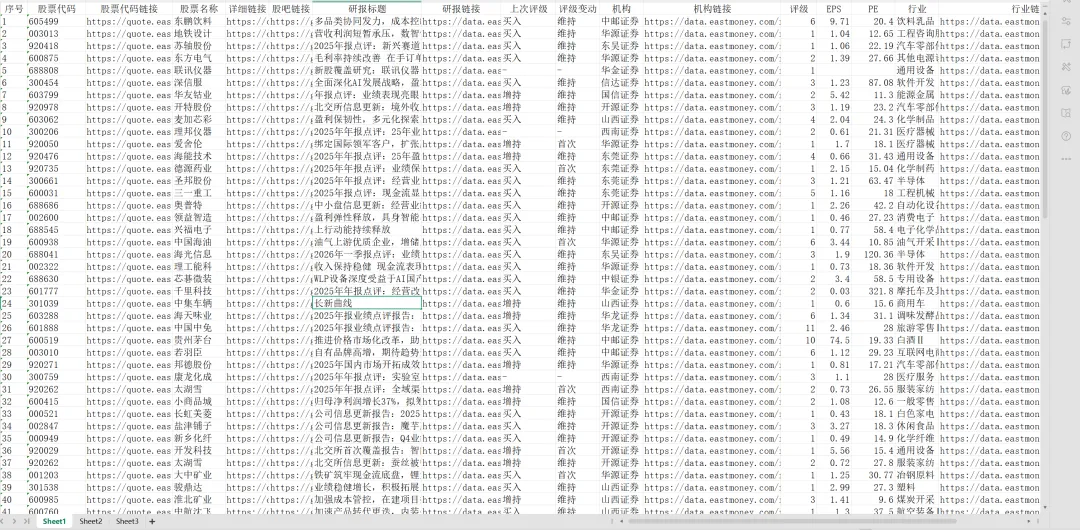
执行前:能看到字段,但链接关系没有被结构化保留,重复抓取也容易反复写入。
执行后:每一条结果都变成了可追溯、可筛选、可扩展的数据资产,流程重复跑也更稳。
7 适用行业 / 可复用价值
这套思路看起来是在做金融研报采集,但真正通用的地方在于它处理的是一类普遍存在的列表型网页问题,所以复用空间很大。
金融研究:个股研报、评级信息、行业栏目、公告列表、机构观点归档。
数据运营:后台报表、运营列表、数据台账、日报采集与历史留痕。
制造与商业分析:供应商名单、竞品情报、招投标公告、政策信息、行业资讯抓取。
通用网页自动化:凡是“表格 + 链接 + 分页 + 去重”组合出现的地方,基本都能沿用这套方式。
交流与分享
这次主要是帮朋友把原来的流程重新理顺了一遍。项目本身不算很重,但思路很实用:拿整行 HTML、做结构化解析、保留关键链接、用 Excel 做历史去重。很多自动化项目后面能不能稳定跑,关键并不是步骤堆得多复杂,而是流程边界和职责划分是否足够清楚。

如果你也在做影刀RPA项目,欢迎交流
扫一扫上面的二维码图案,加我为朋友。
把页面里的可见信息抓下来不难,把链接、结构和历史关系一起沉淀下来,项目才真正具备复用价值。