2026年2月24日,Anthropic干了一件大事。
他们开源了Financial Services Plugins——一整套面向金融行业的AI技能包。DCF估值、可比公司分析、三表财务模型、机构级研报生成......
TechCrunch报了,Bloomberg报了,连普华永道都关注了。
说实话,我看到的第一反应是:这不就是华尔街分析师的全套工具箱吗?
第二反应是:A股呢?
第三反应是:没有。
......
于是我花了6轮迭代,用Claude Code + 免费公开API,给A股搓了一套。
今天完整复盘这个过程。从"看到好东西用不了"的破防,到"自己造一个还挺香"的真香。
此文较长,想看开发过程的看第二部分,想看如何使用和研报截图看第三部分,最后股票爱好者有福利。
Anthropic到底开源了什么?
Financial Services Plugins包含5大类、30+个专业Skills,覆盖了一个投行分析师日常工作的几乎所有环节。
我按功能拆给你看:
📊 估值和财务分析
financial-analysis:dcf — DCF折现现金流估值
financial-analysis:comps — 可比公司分析,行业估值对标
financial-analysis:3-statements — 三表财务模型(资产负债表、利润表、现金流)
financial-analysis:lbo — 杠杆收购模型
financial-analysis:debug-model — 财务模型审计和错误检查
📈 收益和业绩分析
equity-research:earnings — 季度财报分析,EPS趋势
equity-research:earnings-preview — 财报预期,场景分析
equity-research:model-update — 实时更新财务模型
equity-research:catalysts — 催化剂日历,事件驱动分析
🏭 行业和竞争分析
financial-analysis:competitive-analysis — 竞争格局分析
equity-research:sector — 行业整体分析,周期和趋势
equity-research:screen — 股票筛选,机会发现
📋 投资论证和研究报告
equity-research:thesis — 投资论点构建
equity-research:initiate — 研究覆盖启动报告(8-12页完整分析框架)
equity-research:morning-note — 实时新闻和政策影响分析
🏦 投行和私募
investment-banking:datapack-builder — 专业数据包构建
financial-analysis:check-deck — 演示和报告质量检查
还有IC Memo、LBO模型、尽调清单等一堆......
看到这个清单的时候,我的感受大概是这样的:
以前只在券商研报里看到的那些专业框架——DCF三阶段模型、行业可比估值、催化剂事件日历——现在全变成了可调用的Skill。
这意味着什么?
意味着一个普通人,理论上可以生成机构级别的投资分析报告。
不用彭博终端,不用万得,不用年薪百万的分析师团队。
但是......
两个"但是"
但是第一:数据源要钱,而且很贵。
这些Skills需要通过MCP(Model Context Protocol)连接数据源。官方推荐的数据源是:LSEG(伦敦证交所集团)、S&P Global、FactSet、Moody's、PitchBook......
这些都是机构级数据服务,定价应该不菲;我对美股不感冒,不需要。
翻译一下:个人和小团队,基本用不起。
但是第二:只覆盖欧美市场。
所有官方Skills、数据连接器、分析模板,全部基于美国和欧洲市场数据。
A股?没有。
港股?没有。
中国市场本地化?GitHub issue里一堆人在问,官方还没回复。
所以结论很清楚:
框架是开源的,方法论是顶级的,但中国散户一个也用不上。
我在GitHub上看到的评论基本都是:"How to localize to other markets?"、"能否集成免费数据源?"
......
好吧。那就自己搓。
起点:一个想法
既然Anthropic把分析框架和方法论开源了,我能不能:
用这些Skills的方法论作为分析框架
用免费公开API(东方财富等)替代付费数据源
针对A股市场特点做本地化调整
用Claude Code来编排和迭代
核心思路:Skills当方法论教材,免费API当数据引擎,Claude Code当施工队。
Step 1:计划——先看清楚再动手
我没有一上来就写代码。
先让Claude Opus 4.6审查了Haiku之前生成的开发计划,发现了5个关键问题:
原计划完全忽略了financial-services-plugins的Skills——这些才是核心方法论
缺少HTML仪表盘——只有Word报告不够直观
开发顺序错了——应该先搭框架再接数据,不是先写爬虫
Skill名称搞错了——得用实际可调用的名称
没有把equity-research:initiate的机构报告结构作为对标标准
修正后的计划:5步走,16个模块,用12个Skills的方法论,全部数据免费。
这一步的教训:让AI互相审查比自己review效率高十倍。也顺便说明了一件事——Claude Opus 4.6确实比Haiku靠谱,至少在做计划这件事上。(Haiku:你礼貌吗?)
Step 2-4:三个维度,逐步搭建
根据A股投资的实际需求,我设计了三维度分析体系:
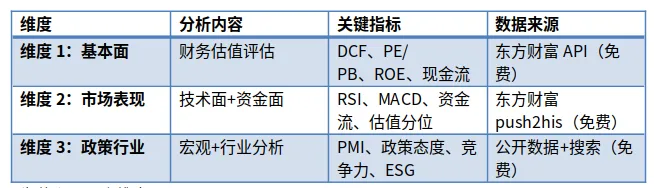
为什么是三个维度?
因为A股不同于美股——你不能只看基本面。政策一变、资金一转、行业风口一换,基本面再好的公司也能跌你一脸。
所以维度2和维度3,是我专门为A股加的。官方Skills里没有这个设计。
每个维度独立评分,最后通过融合引擎算综合评分、交叉验证、生成投资建议。
这就好比:维度1是体检报告,维度2是体能测试,维度3是心理评估。三个都过了才算"健康"。光看体检单说"指标正常"就冲进去——在A股,那叫"送人头"。
Step 5:报告 +仪表盘——让结果可用
分析完了,总得有个像样的输出。
我搓了两个生成器:
DOCX报告生成器(436行代码)——8章结构:
封面 → 执行摘要 → 公司基本面 → 市场分析 → 政策行业 → 融合分析 → 投资建议 → 风险提示 +附录
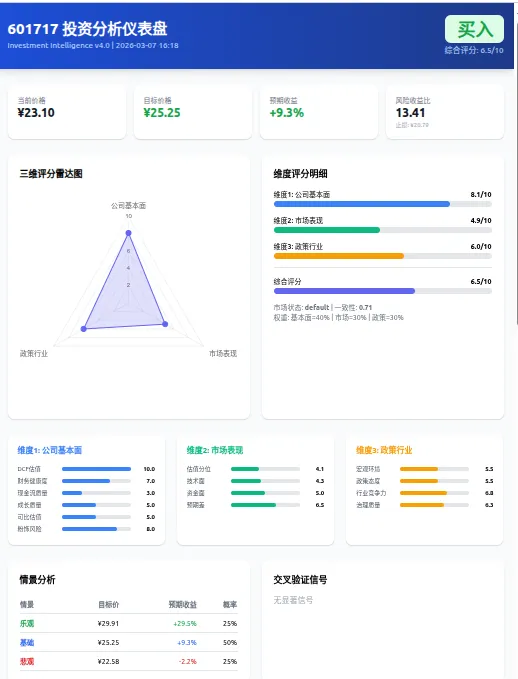
HTML仪表盘(367行代码)——
三维雷达图(Chart.js)+评分条 + 组件卡片+ 情景分析表 +交叉验证信号
一个命令跑下来,同时生成Word报告和交互式网页仪表盘。
用601717(中创智领)测了一下:
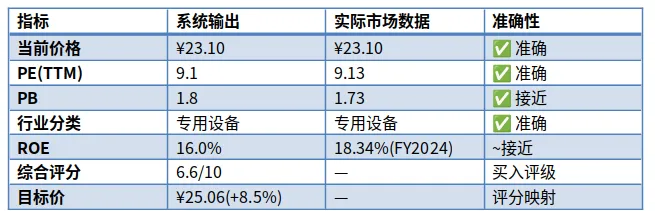
核心数据准确度很高。ROE有一点偏差是因为API返回的财务数据期数差异——不是系统算错了,是数据源还没更新到最新年报。
但我没有到这里就停下来。
因为一个负责任的开发者和一个不负责任的开发者之间的区别,就在于:你有没有想过"如果这个数据错了会怎样"。
Step 6:核验层——因为准确性是生命线
用AI做投资分析,最大的风险不是"分析错了",而是"你不知道哪里可能错了"。
一份信心满满但错误百出的报告,比没有报告更危险。
我先问Opus如何确保报告出来是准确的,它回答:

为了提升报告的可信度,我采取GAN(Generative Adversarial Networks)的方式,将Opus的回答发给豆包和Deepseek,让它们来挑刺,将挑刺的结果再返回给Opus,让它反思和改进计划。
所以第6轮迭代,我加了两个关键模块:
🔍实时事件搜索(event_searcher.py)
用DuckDuckGo搜索公司/行业/宏观最新事件(要质量高的其它搜索需要订阅费)
关键词情绪分析
防止报告与现实脱节——比如公司刚被证监会立案调查,你的报告还在说"买入"。这种事一旦发生,用户骂你是轻的。
✅投资者核验层(validation_layer.py)
数据信心评级——区分"硬数据"和"模型推算"
逻辑一致性检查——营收大增但现金流为负?标红
压力测试——如果假设全错了,最坏能亏多少?
尾部风险识别——那些概率小但后果严重的事件(比如突然退市,嗯A股特色)
最终报告结构变成了这样:
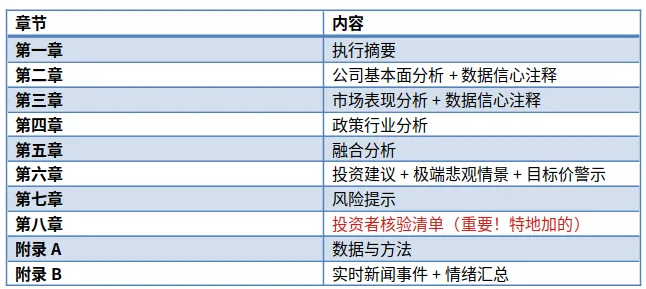
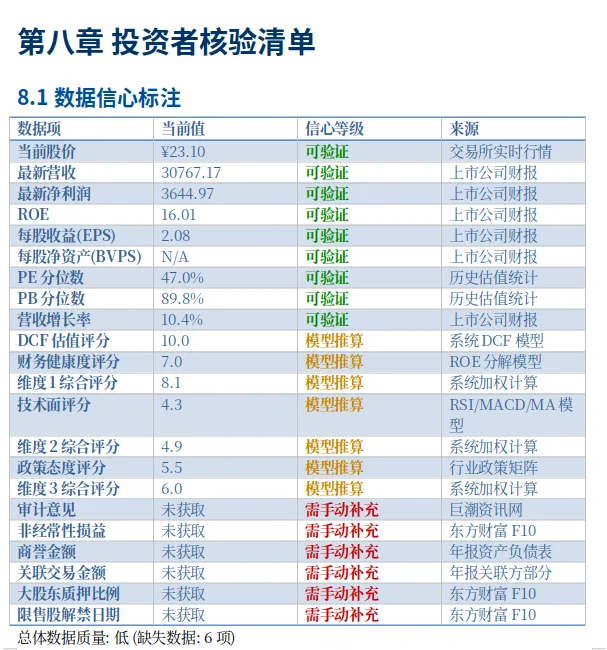
第八章"投资者核验清单"是我最满意的部分。它直接告诉你:
哪些数据是高信心的(可直接信)
哪些需要你自己去核实(标出核验方法)
逻辑链上有没有矛盾
压力测试结果如何
有哪些尾部风险你应该关注
这不是一份"告诉你答案"的报告,而是一份"帮你做完作业但标出哪里需要你自己检查"的报告。
就像高考答案解析——答案给你了,但推导过程和易错点也标出来了。你可以抄答案,但我建议你看懂解析。
自然对话
 一行代码跑完整分析
一行代码跑完整分析
from src.orchestrator import InvestmentIntelligenceOrchestrator, AnalysisInputo = InvestmentIntelligenceOrchestrator()r = o.analyze(AnalysisInput( ticker='601717', include_dimensions=[1, 2, 3], report_format='both'))
或者更简单——Shell一把梭:
bash analyze.sh 601717
跑完自动生成三个文件:
601717_report.docx — 专业投资报告
601717_dashboard.html — 交互式仪表盘(三维雷达图)
601717_analysis.json — 原始分析数据
批量分析也行:
tickers = ['600519', '601717', '300502']for ticker in tickers: o.analyze(AnalysisInput(ticker=ticker, report_format='both'))
三只股票,三份报告+ 三个仪表盘,一个循环搞定。
UI反应是这样的(仅作示意):
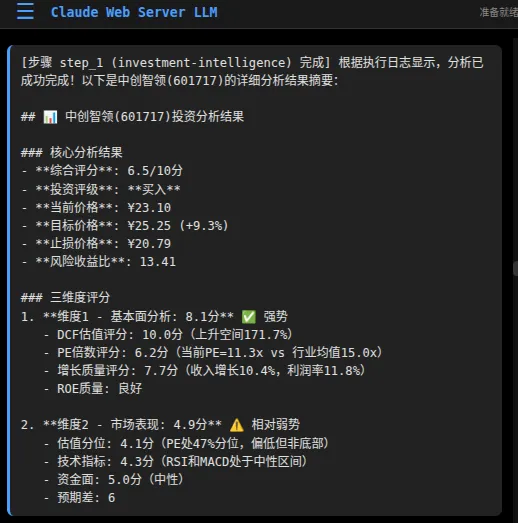
报告是这样的(仅作示意):

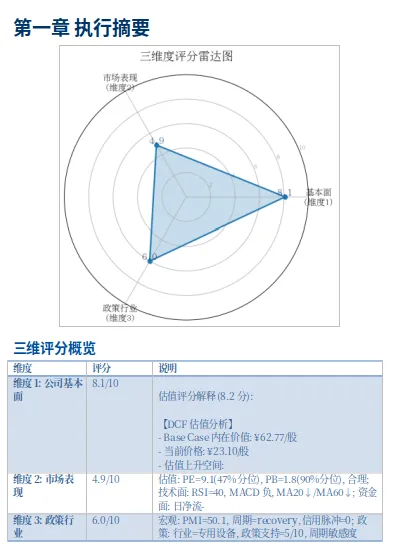
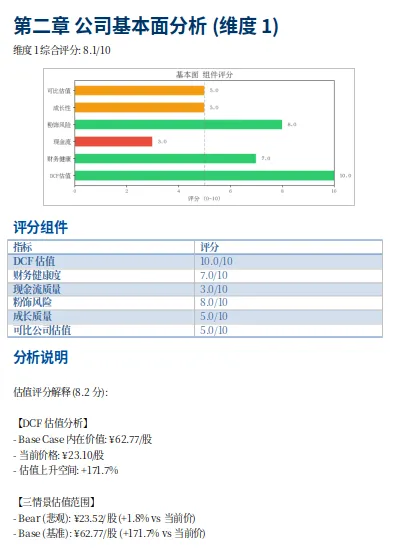
仪表盘这样(仅作示意):

以前做这些需要什么?一个CFA持证人+ 一个万得终端 +大概三天时间。
现在?在我的web服务器网页上一句话或一个命令。
(CFA持证人:你礼貌吗?×2)
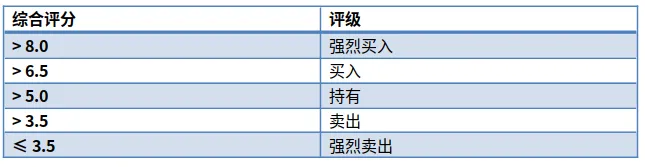
评级标准
使用原则(比报告本身更重要)
这一部分我要认真说。因为我见过太多人拿到AI的输出就无脑执行。
我给自己和用户定了一份审核清单:
✅ 必做:
股价、市值、PE/PB 与东方财富/同花顺实时对比
营收、净利润、ROE 与年报/季报交叉验证
估值假设是否明确写出(增长率、折现率、终值增速)
是否给出悲观/基准/乐观多情景
❌ 危险信号(出现任一条就慎用):
数据老旧、来源不明
只给结论,不写假设条件
估值大幅偏离同行,无合理解释
只讲利好,完全不提风险
用"肯定""必然""一定大涨"等绝对化表述
五条核心原则:
只信可验证数据,不信预测和评级
目标价当参考,不当买卖指令
决策自己做,软件只当信息工具
任何AI结论,都要再核对一次官方信息
预测越确定、越夸张,越要警惕
这套系统能做什么?
✅ 三维度分析(不局限于单一指标)
✅ 多维度交叉验证,发现逻辑矛盾
✅ 采用真实市场数据(非虚构假设)
✅ 保守预估(悲观/基准/乐观三种情景)
✅ 自动标注数据信心等级和核验要求
✅ 实时事件搜索,防止报告与现实脱节
✅ 一键生成DOCX报告 + HTML仪表盘
还有什么做不到?
说实话,也有不少局限:
⚠️ 技术面某些API连接不稳定(push2his的TLS指纹问题,K线数据偶尔拿不到)
⚠️ 财务数据可能滞后1-2个报告期(取决于东方财富API更新速度)
⚠️ 目标价本身具有不确定性——模型假设微小变动就可能导致价格大幅波动
⚠️ 不能也不该预测短期(1个月内)涨跌
但这些局限,我在报告里都标出来了。一个工具的可信度,不取决于它说对了多少,而取决于它有没有告诉你它可能错在哪。
回顾这个过程:
Anthropic开源了华尔街级别的分析工具 → 发现A股用不了 → 自己搓了一套 → 用免费API替代付费数据源 → 针对A股特点加了三维度分析 → 6轮迭代逐步完善 → 加了核验层防止"AI幻觉害人"
全程用Claude Code做的(这次人肉debug都没有)。不需要FactSet,不需要Bloomberg Terminal,不需要年薪百万的分析师。
需要的是:一个清晰的需求+ 一点编程能力+ 持续迭代的耐心+ 对准确性的执念。
这大概就是AI时代的"研报自由"——不是免费得到机构的结论,而是免费获得机构的方法论,然后用自己的数据跑出自己的结论。
当然了,如果你跑出来的结论是"强烈买入"然后亏了......
那就是你的分析水平问题,不是工具的问题。(开玩笑的。但免责声明还是要看的。)
💬 想看完整的分析报告?
在公众号后台回复"601717, 300394, 000338",获取:
完整的分析报告样本(DOCX)
HTML交互式仪表盘
(仅仅是为了请您帮助我看看哪些方面需要改进,不做投资建议)
💬 发现Bug或有改进建议?
直接在评论区告诉我。这套系统还在持续迭代,你的反馈就是下一轮优化的需求文档。
📌觉得有用?收藏备用,下次选股前翻出来看看。
🔄身边有炒股的朋友?转发给TA,一起告别"看天吃饭"。
💬你平时用什么工具分析股票?评论区聊聊,互相种草。
⚠️免责声明:本文涉及的所有投资分析内容仅供技术学习和参考,不构成任何投资建议。股市有风险,投资需谨慎。所有分析结论请务必与官方数据交叉验证后再做决策。AI生成的目标价和评级仅为模型推算结果,不代表对未来市场表现的任何承诺或保证。