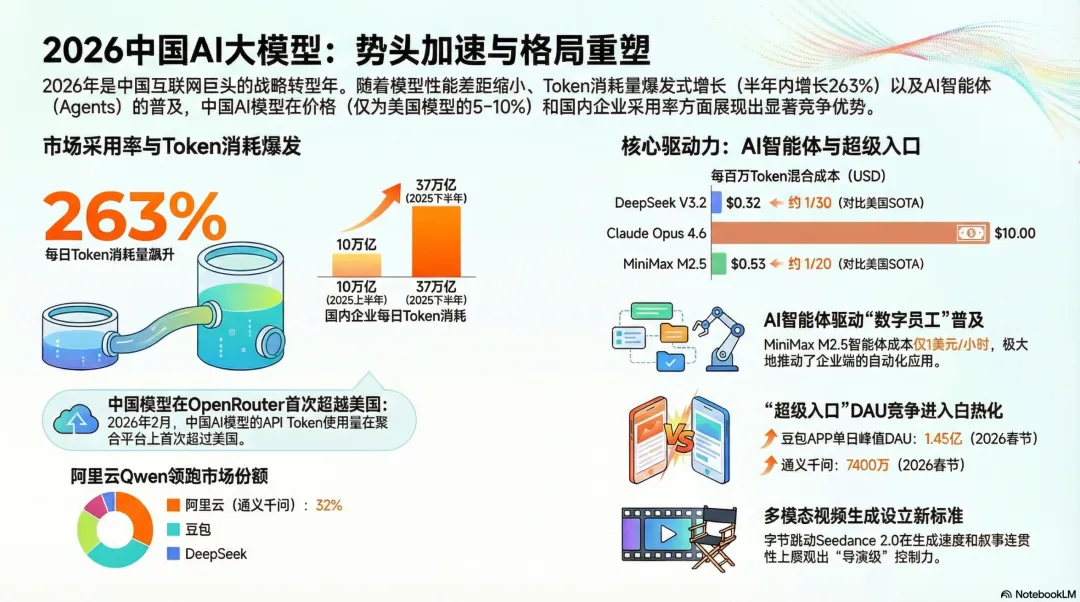
高盛研报-深度解析:中国AI模型上演逆袭,全球算力“定价权”悄然生变高盛在报告中乐观预测了全球基础模型产业的收入规模:预计到2030年,仅订阅和API收入池就将达到4720亿美元,2024年至2030年的年复合增长率高达88%。看看中国AI模型公司的情况,近期估值近期大幅飙升(例如智谱AI年内上涨322%),反映出投资者正在积极寻找“中国的Anthropic或OpenAI”。凭借极致的性能价格比、快速迭代的产品能力,以及庞大的本土应用市场锤炼,中国AI模型公司已经从一个区域的参与者,成长为全球AI算力基础服务市场中不可忽视的、甚至在某些领域开始引领规则的强大力量。在第三方API聚合平台OpenRouter上,2026年2月以来,调用中国AI模型的API令牌(Token)使用量,历史上首次超过了美国模型。以2月26日的数据为例,当月至今的Token使用量排名中,MiniMax的M2.5模型(5.02万亿Token)、Moonshot AI的Kimi K2.5(4.18万亿Token)和智谱AI的GLM-5(1.81万亿Token)等中国模型强势占据了榜单前列。性能差距急剧收窄:以MiniMax M2.5、Kimi K2.5、GLM-5为代表的新一代中国模型,在长上下文(最高支持100万Token)、智能体(Agent)能力和整体性能上,与美国最先进的SOTA模型差距已非常小。“价格屠夫”式竞争力:这是最关键的杀手锏。中国头部模型的定价,仅为美国旗舰模型(如GPT、Claude)的5%-10%。例如,根据Artificial Analysis的数据,DeepSeek、MiniMax、Kimi等模型的混合定价在每百万Token 0.32至1.6美元之间,而美国主流模型则在4.5至10美元区间。如此极致的性价比,对全球开发者尤其是初创企业和需要高频调用的AI Agent应用,构成了无法抗拒的吸引力。AI Agent需求爆发:全球范围内AI智能体应用的快速普及,催生了海量、低成本的API调用需求。中国模型凭借价格和时延优势,迅速成为这股浪潮的主要“算力燃料供应商”。面向消费者的应用端,2026年春节,成为中国互联网巨头争夺下一代AI消费级“超级入口”的关键战役。根据QuestMobile数据,春节期间(以2月16日除夕为例),三大AI助手的日活跃用户数达到峰值:字节跳动-豆包:峰值DAU高达1.45亿,一骑绝尘。C端战役的关键,不再仅仅是对话的“智能感”,在于完成任务的能力、无缝的交易闭环,以及社交与推送功能。谁能将AI助手与用户的真实生活、工作流更深度地绑定,谁就更可能赢得这场关于未来流量分发的“入口革命”。与消费端的红包战相比,企业级市场的增长更为惊人,根据Frost & Sullivan的数据,中国企业的日均AI Token消耗量从2025年上半年的10.2万亿,暴增至下半年的37万亿,环比增长263%。市场格局也迅速集中:阿里巴巴(通义千问):市场份额从17.7%大幅跃升至32.1%,近乎翻倍。这得益于其模型深度集成到阿里云及自身电商、编码等业务流程中。字节跳动(豆包):份额从14.1%升至21.3%。DeepSeek:份额从10.3%升至18.4%。企业级AI应用的爆发,直接转化为对云计算和数据中心需求的强劲拉动。高盛因此上调了对阿里巴巴未来三年的资本开支预测至5130亿元人民币,并预计阿里云营收在2025年12月及2026年3月季度将实现38%和37%的同比增长。报告明确指出,“云与数据中心”是其当前最看好的子板块。