今天解读的这份白皮书是由VIAVI Solutions发布,标题为《AI/ML 数据中心网络验证》,旨在探讨AI/ML工作负载对现代数据中心网络带来的挑战,并介绍相应的测试解决方案。
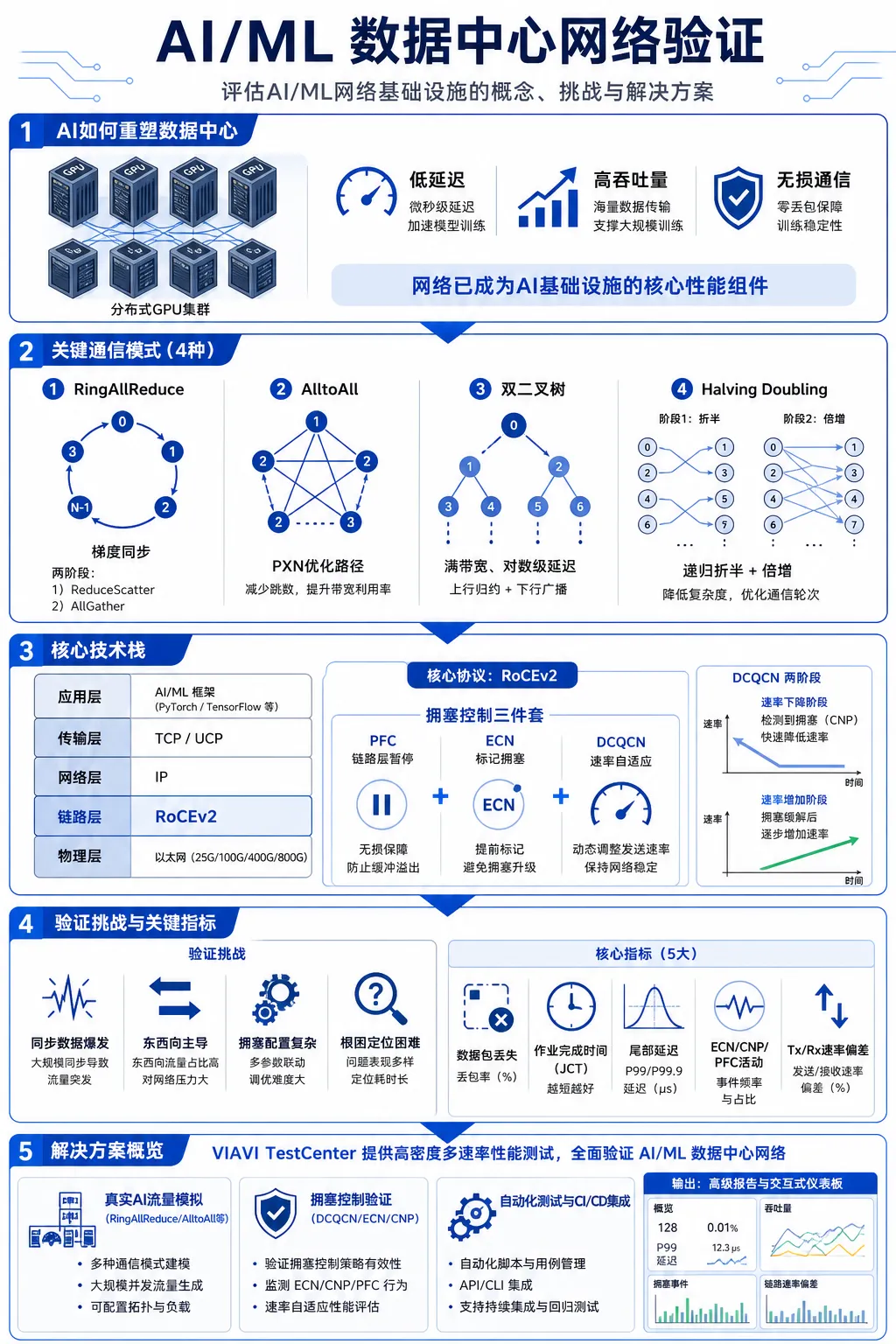
一、核心背景:AI如何重塑数据中心
规模与复杂性剧增:AI和机器学习工作负载(特别是训练万亿参数模型)的规模和复杂性,要求数据中心部署数千个GPU/xPU,并通过高速互连网络连接。
关键性能要求:AI工作负载对网络提出严格要求,包括:
低延迟:任何额外的延迟都会拖慢整个训练进程。
高吞吐量:需要处理海量数据。
无损通信:数据包丢失会导致训练停滞。
网络成为核心瓶颈:网络不再是简单的连接,而是AI基础设施中关键的性能组件。
二、AI工作负载的关键网络概念
白皮书详细解释了AI训练中特有的网络通信机制。
1. AI流量模式与集合通信库 (CCL)
流量特点:
包含大量“大象流”(大流量)。
数据和计算密集型。
需要大量短小的远程内存访问操作。
节点间同步启动,任何一个流延迟都会拖慢整体进度。
集合通信库 (CCL):实现多个进程间高效数据交换和同步的软件库。NVIDIA的NCCL是典型代表,用于实现神经网络的分布式训练。
2. 四种关键通信模式
白皮书重点介绍了NCCL中三种主要的通信算法,用于实现梯度同步:
RingAllReduce(环状全归约):
优点:带宽利用率高。
原理:将设备排列成逻辑环。
阶段:
ReduceScatter(归约分散):数据被分成N块,在每个设备间循环传递和求和,最终每个设备持有一部分求和结果。
AllGather(全收集):每个设备将自己持有的部分结果传递给下一台设备,经过N-1步后,所有设备都获得完整的最终求和结果。
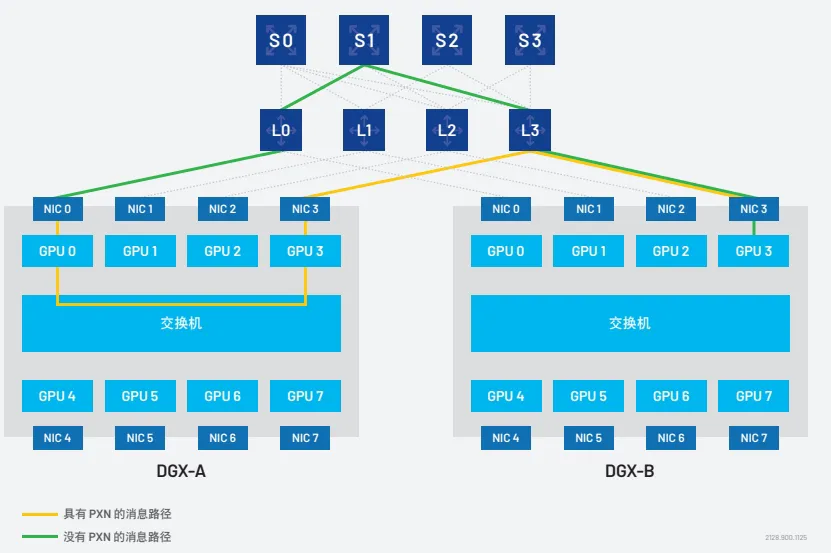
AlltoAll(全对全):
原理:集群中的每个处理器都与其他所有处理器交换数据。
挑战:通信密度极高,对交换结构要求极高。
优化:NVIDIA NLL引入了PXN功能,通过优化消息路径(减少网络跳数)来降低争用,提高性能。
双二叉树(Double Binary Tree):
优点:提供了满带宽和对数级的低延迟,甚至低于2D环。
原理:利用两个互补的二叉树。在第一棵树中,一半节点做“节点”,另一半做“叶”;第二棵树角色互换。
Halving Doubling(折半倍增):
原理:结合了递归折半和距离倍增。在ReduceScatter阶段,进程数量逐步规约,距离逐步倍增;在AllGather阶段则相反。
流程:通过多步递归操作,最终完成所有数据的归约和分发。
三、核心技术:RoCEv2及其拥塞管理
RoCEv2(基于融合以太网的RDMA第2版):
特点:基于标准以太网,支持UDP封装跨三层路由,便于大规模部署。
作用:实现远程直接内存访问,绕过CPU和内核,实现低延迟、高带宽的数据传输。
拥塞管理机制:RoCEv2的有效运行依赖无损传输,需要以下协议配合:
流程:发送方(反应点)发送流量 ➔ 交换机(拥塞点)标记ECN ➔ 接收方(通知点)发送CNP(拥塞通知数据包)回发给发送方。
行为:发送方收到CNP后,成倍降低传输速率(速率下降阶段);如果一段时间无拥塞,则逐渐增加速率(速率增加阶段)。Alpha参数用于控制下降速度。
PFC(优先级流量控制):第2层机制,当交换机缓冲区满时,发送暂停帧通知上游设备停止发送特定优先级的流量,防止数据包丢失。
ECN(显式拥塞通知):第3层机制,交换机在检测到拥塞时,在数据包IP头中标记ECN位。
DCQCN(数据中心量化拥塞通知):
总结:DCQCN是主要拥塞管理机制,PFC作为故障安全解决方案。
四、常见AI测试挑战
同步数据爆发:AI工作负载产生大量同步数据流,容易导致网络缓冲区溢出。
东西向流量主导:AI训练以GPU之间的横向数据移动为主,对交换结构的全网状通信能力要求高。
拥塞管理配置复杂:PFC、DCQCN等协议配置不当会导致丢包、训练延迟或链路利用率低。
QoS配置错误:不正确的VLAN标记、队列映射或缓冲区分配会悄无声息地降低性能。
根因定位困难:问题通常涉及多组件和多网络层,且相互依赖性强。
五、揭示网络健康状况的统计数据与问题指标
关键可观测指标:
数据包丢失:关键更新失败。
作业完成时间 (JCT):整体训练效率。
尾部延迟:最坏情况下的延迟,是主要性能杀手。
丢弃/重排数据包:拥塞或ECMP问题。
Tx/Rx速率偏差:链路未充分利用或流量不平衡。
ECN/CNP/PFC活动:对拥塞控制机制的深度洞察。
问题与原因对应表:
丢包 ➔ PFC阈值错误或缓冲区溢出。
尾部延迟 ➔ 流路径不平衡或资源争用。
高JCT方差 ➔ ECN/CNP响应不一致或队列堆积。
拥塞但速率不降 ➔ ECMP或拓扑需要优化。
六、VIAVI TestCenter AI测试解决方案
硬件平台:
A1-400-QD-16:最多16个400G端口,支持100G/200G/400G上的RoCEv2,适合多用户、多速率环境。
B3平台:支持QSFP-DD和OSFP 800G接口,提供高达6.4 Tbps的流量生成,端口密度业界领先。
核心能力:
流量模拟:精确模拟真实的AI工作负载,包括基于RoCEv2的流量和CCL模式(AlltoAll, RingAllReduce等)。
拥塞控制验证:内置对DCQCN、ECN和CNP的支持,可在动态拥塞下验证这些机制的性能。
性能基准测试与压力测试:模拟东西向流量,在流量不平衡条件下对网络进行压力测试。
自动化与集成:支持不同帧大小、数据大小和流量模式的测试,并兼容CI/CD工作流。
诊断与报告:提供高级报告和交互式仪表板,帮助识别瓶颈、微调设置并验证工作负载就绪性。
七、结论
核心观点:AI工作负载的扩展给网络架构带来了前所未有的压力,任何微小的延迟或抖动都会导致性能大幅下降。
行动建议:组织需要采用反映AI流量独特需求的测试策略和工具(如VIAVI TestCenter),通过模拟AI流量、测量JCT、丢包和尾部延迟,早期发现并解决问题。
最终目标:通过集成的流量仿真、性能基准测试和流级分析,帮助网络和基础设施团队做出明智决策、降低部署风险,并提供能够满足AI大规模计算需求的可靠、可扩展的基础设施。
总结: 这份白皮书系统性地阐述了AI/ML工作负载如何颠覆传统数据中心网络,深入解释了支撑现代AI训练的核心通信算法(RingAllReduce, AlltoAll, 双二叉树等)和关键传输技术(RoCEv2及其拥塞控制)。同时,它指出了当前AI网络测试面临的独特挑战,并详细介绍了VIAVI的TestCenter解决方案如何通过精准的流量模拟、性能测试和深入分析,来确保AI数据中心网络的高性能、可靠性和可扩展性。
往期内容
研报解读|拆开一台价值400万美元的AI服务器,里面到底装了啥?
研报解读|《AI in Capital Markets: Balancing Innovation and Integrity》
AI使用观察|写作工具在流血,代码工具在疯涨:AI的能力分化已经开始
AI使用观察 | 10亿人在用AI,但绝大多数只是"到此一游"
研报解读|AI烧的不只是电:AI一天"喝"掉3.8亿升水 ,一份没人敢看的联合国报告
研报解读|《面向下一代 AI 基础设施 800V 直流架构白皮书》
研报解读|《AI 在端点管理与安全融合中的关键作用分析报告》
研报解读|你正在用的AI,可能已经成了黑客的武器,HiddenLayer 2026 AI威胁报告深度解读
研报解读|摩根士丹利《2026年中国新兴前沿领域:人工智能路径-以更低算力成本实现更高智能回报报告》
研报解读|一图看懂“AI原生工作流”:你和AI的高效协作,就靠这10个关键词
研报解读|爱立信《2026 从数据混乱到 AI 就绪的数据网格》白皮书
研报解读|《代理型 AI 的未来:前瞻报告》看懂AI从工具到助手的巨变,抓住机遇规避风险
研报解读|《OpenAI:AI 就业转型框架:人工智能对就业的短期影响研究》
研报解读|中国信通院《2026智能算力服务全景解读:万亿市场、四大趋势、全产业链机遇》
研报解读 | 世界经济论坛重磅报告:AI不是工具,是组织革命!90%企业还在做无用功
研报解读 | BCG 2026重磅报告《AI优先型企业制胜未来:财产与意外伤害险研究报告》
研报解读 | 华为AI安全白皮书深度解读:AI不是黑箱,安全才是底线
研报解读 | 华为《AI DC 白皮书》重磅发布:算力成为新“黑金”
研报解读 | 2026计算机行业重磅展望:国产算力全面突破,AI应用迎来爆发元年
研报解读 | 高盛2026年AI报告核心解读:AI不会“吃掉”软件,但会彻底重构软件行业
研报解读 | 摩根士丹利《全球科技行业研究:存储领域-如何布局新的AI瓶颈》
研报解读 | AI指数报告深度解读及对2026年数据行业的影响分析
研报解读 | 2026 AI 代理五大趋势:重塑商业的核心变革来了!
政策解读 | 2026数据市场新政落地!全国一体化加速,算力将成AI落地核心抓手