
在金融研究机构中,经常会遇到要把专业研报发布到公众号,由于专业研报的主要受众是专业投资者,可能会出现投资评级、目标价、个股建议等内容。但公众号的读者包括大量普通投资者。为了降低合规风险,研报在改写成公众号文章之前,往往需要先做一轮“脱敏”:删掉不适合公开传播的个股投资建议、主观判断和过于明确的结论。
本文介绍如何通过AI方式进行报告脱敏。

研报脱敏这件事听起来像是简单的文字处理,实际做起来并不轻松。
一篇行业研报少则五六千字,多则一两万字。合规人员需要逐句判断哪些内容可以保留,哪些内容需要删除,哪些内容可以改成更中性的表述。改完之后,合规或运营人员还要再审一遍。如果中间有分歧,还要来回沟通。
一篇文章从研报原文变成公众号稿件,花上一两个小时并不少见。遇到集中发布的时候,这个流程会明显拖慢内容分发效率。
于是我尝试做了一个AI研报脱敏助手。
它的目标很简单:先让 AI 帮人把高风险内容标出来,再由研究员和合规人员确认处理。整个过程中,AI 不直接替人做最终决定,而是把原来需要从头通读的工作,变成有重点地核查和修改。
这不是简单的关键词替换
最开始容易低估这件事。
如果只是删除“买入”“目标价”“盈利预测”这类明显词语,传统规则也能做。但研报脱敏的难点,往往不在这些显眼词上。
比如下面两句话:
预计今年行业规模将达到 500 亿元。
预计某公司今年收入将达到 60 亿元。
两句话结构很像,处理方式却不同。前一句是行业层面的判断,通常可以保留;后一句涉及具体公司预测,就需要谨慎处理。
再比如,有些句子表面上没有公司名,但上一句刚刚提到某家公司,下一句用了“其”“该企业”“龙头”等代称。这时候如果只看单句,很容易漏掉风险。
所以这个工具不能只靠关键词。它需要理解上下文,也需要一套清晰的判断规则。
规则是用真实报告磨出来的
这个工具最重要的部分,不是界面,也不是模型调用,而是一套可执行的脱敏规则。
规则不是一次性写出来的。我的做法比较笨,但有效:
1. 选一篇真实研报,让 AI 按当前规则跑一遍;
2. 把 AI 标出的内容和人工判断逐条对比;
3. 记录漏标、误标和边界不清的地方;
4. 分析原因,看是不是规则本身需要调整;
5. 只把稳定、可复用的问题沉淀进规则。
这里有一个很重要的经验:不是每个错误都要立刻改规则。
有些错误只是某篇文章的特殊写法,如果为了它把规则写得很复杂,可能会影响其他正常场景。规则越复杂,边界问题也会越多。每次调整之前,都要先判断这是系统性问题,还是偶发问题。
经过几轮迭代后,规则会逐渐稳定。但它不会真正“完成”。新的行业、新的题材、新的写法,都会带来新的判断场景。这个过程更像是持续维护一份业务规则手册。
几个关键产品设计
1. 不让 AI 直接改原文
如果 AI 直接改了原文,研究员不知道它改了哪里,合规人员也很难逐条复核。尤其在合规场景里,修改痕迹和判断依据非常重要。
因此我让 AI 在原始 Word 文档上加批注和高亮,告诉用户哪里可能有问题、建议怎么处理。最终删不删、怎么改,仍然由人确认。
用户打开文档后,可以清楚看到 AI 标了哪些地方,不会担心文章被悄悄改掉。
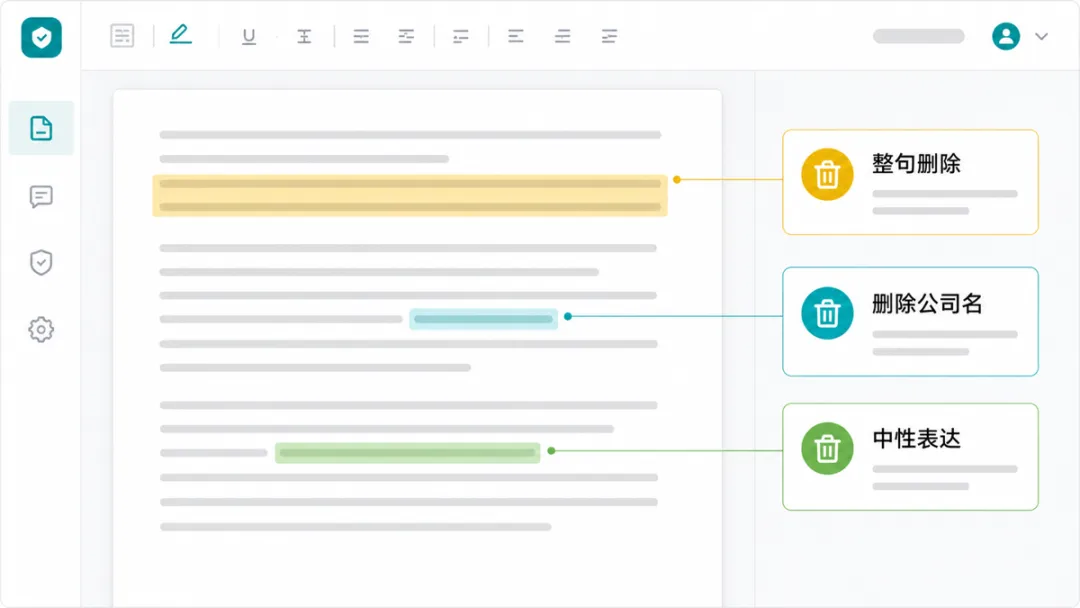
2. 用颜色区分处理方式
工具没有把所有问题都统一标红,而是用了不同颜色区分处理建议。
比如:
黄色:建议整句删除;
青色:建议只删除句子里的公司名;
绿色:建议改成更模糊、更中性的表达。
颜色在这里不是装饰,而是一种信息分层。
研究员和合规人员扫一眼文档,就能大致知道这篇文章的处理工作量。合规人员复核时,也可以先看风险更高的内容,再看局部替换类问题。
3. 先出问题清单,再写入文档
AI工具运行后,不会马上往 Word 里写批注,而是先生成一张问题清单。
清单里会列出每一处疑似风险内容,包括所在段落、风险类型、处理建议和理由。用户确认后,再把批注和高亮写入文档。
这个步骤看起来多了一步,实际能减少很多不必要的麻烦。
用户可以在执行前先看一遍,如果发现明显误判,可以先排除。整个过程也更像是在审核 AI 的建议,而不是被动接受 AI 的处理结果。
4. 批注里直接写出修改后的句子
一开始,批注里只写“建议删除公司名”“建议删除盈利预测”这类说明。
后来发现,这对使用者不够友好。研究员看到批注后,还要自己判断删完之后句子是否通顺,改起来并不省事。
于是我们把批注改成更具体的形式:不仅说明要处理什么,还直接给出处理后的完整句子。
比如原句里有一串公司名,AI 会在批注里写出删除公司名后的版本。研究员只需要对照确认,再决定是否采纳。
这个小改动对效率提升很明显,也降低了人工修改时出错的概率。
踩过的几个坑
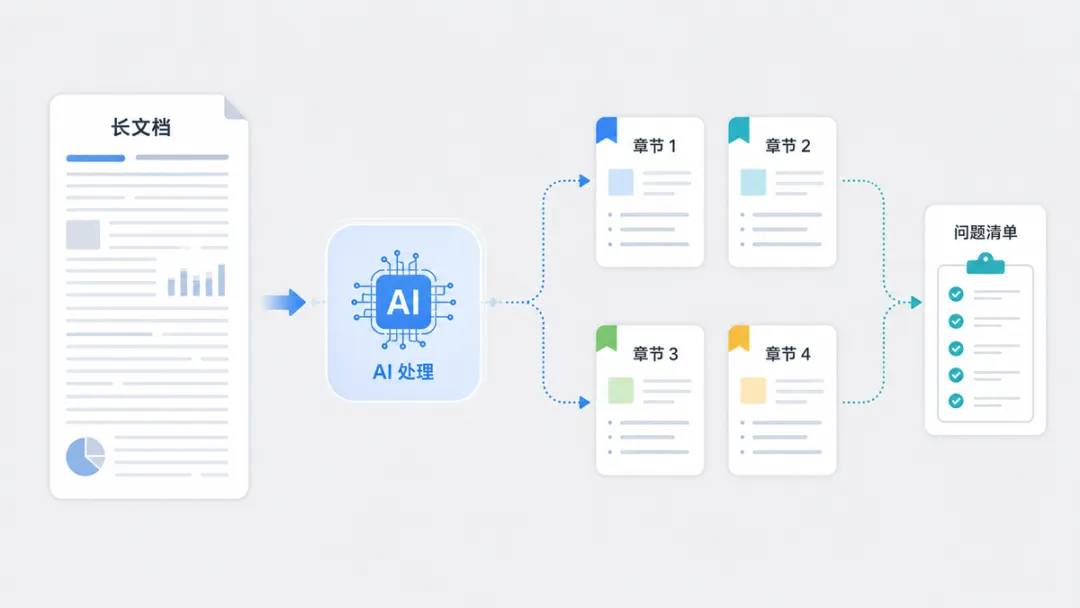
1. 长文档容易漏标
一篇一万多字的研报,如果整篇一次性交给 AI 处理,前半部分效果通常还不错,后半部分更容易出现漏标。应该是大模型的长文档处理注意力衰减原因导致
后来我们改成按章节处理。每个章节单独识别风险内容,再汇总成完整结果。这样做虽然流程多了一步,但稳定性明显更好。
长文本任务不要总想着一次性解决。把大任务拆成小任务,往往更可靠。
2. 主观判断和客观描述的边界很细
研报里有很多表达,本身并不违规,关键要看它指向的是行业、公司,还是具体投资建议。
例如“景气度提升”“竞争优势明显”“有望持续受益”这类表述,如果用于行业分析,可能问题不大;如果明确指向某家公司,就需要谨慎。
这类判断不能完全交给模型自由发挥。必须把业务规则写清楚,让 AI 知道哪些情况要删,哪些情况可以保留,哪些情况需要提示人工判断。
3. 技术报错不能直接丢给业务用户
这个工具底层由 AI 和脚本协同完成,运行过程中难免会遇到文档格式异常、解析失败、写入失败等问题。
如果把原始报错直接展示给研究员或合规人员,他们很难知道下一步该怎么办。
后来我们在上层做了封装,把技术报错翻译成业务能理解的话。比如提示用户“文档中可能存在特殊格式,请另存为标准 Word 后重试”,而不是显示一串程序错误。
AI 工具要进入真实业务流程,不能只考虑核心能力,还要处理这些看似琐碎的异常场景。
最后沉淀成一个可复用的 Skill
经过多轮迭代后,我们把脱敏规则、处理流程、输出格式和注意事项,整理成了一份结构化的 Skill 文档。
可以把 Skill 理解成一份给 AI 使用的操作手册。
它会告诉 AI:
· 这项任务的背景是什么;
· 哪些内容属于高风险;
· 遇到不同类型内容时应该怎么处理;
· 输出结果要包含哪些字段;
· 哪些情况必须提示人工复核。
这份 Skill 的价值在于,它把原来分散在人工经验里的判断标准,变成了一份可以阅读、修改、复用的文档。
如果后续发现某类内容经常误判,只需要更新 Skill 里的规则。下次处理研报时,AI 就会按照新的规则执行。
对合规场景来说,这一点很重要。因为合规人员可以直接看懂这份文档,知道 AI 的判断依据来自哪里,也可以参与规则修订。
效果和边界
工具上线后,一篇研报的脱敏处理时间,从原来的一两个小时,压缩到大约二三十分钟。
节省的时间主要来自两个地方:
第一,研究员不用从头到尾逐句找风险点,可以先看 AI 标出的内容;
第二,合规复核时可以围绕标注结果展开,沟通成本更低。
不过,这个工具也有明确边界。
AI 标注不可能做到 100% 准确,漏标和误标都会出现。人工复核不能省,最终责任也仍然在人。
新题材、新行业、新写法出现时,规则还需要继续磨合。尤其是一些边界很细的表达,仍然需要合规人员根据具体语境判断。
所以我们对这个工具的定位一直很清楚:它是辅助工具,不是自动合规系统。
几点启发
做完这个工具后,我对 AI 产品落地有几个更具体的感受。
第一,合规类 AI 工具不能只追求自动化程度。很多时候,让 AI 把问题找出来、解释清楚、交给人确认,比直接让 AI 完成修改更稳。
第二,业务规则比提示词更重要。提示词可以让模型短期表现更好,但真正能沉淀下来的,是一套可维护、可复用、可审计的规则体系。
第三,用户信任来自可控感。用户要知道 AI 做了什么、为什么这么判断、自己能不能修改。只要这些问题说不清,工具再聪明也很难进入正式流程。
第四,异常处理很影响体验。很多 AI 工具在演示时效果不错,但一进入真实文档、真实流程、真实用户环境,就会遇到各种细节问题。能不能把这些问题处理好,决定了工具能不能长期使用。

结语
研报脱敏助手看起来只是一个小工具,但它背后涉及 AI 产品落地中很典型的一类问题:如何把人的业务经验整理成规则,形成一个可复用的技能,再让 AI 按规则稳定执行。
在这个过程中,模型能力很重要,但真正决定效果的,往往是业务边界、流程设计和人工复核机制。
AI 可以承担大量重复判断和初筛工作,但规则怎么定、结果怎么审、责任怎么留痕,仍然需要产品、业务和合规一起设计。
这也是我认为这类工具最有价值的地方:它不只是节省了几十分钟处理时间,更重要的是把原来靠经验流转的工作,逐步沉淀成了可以复用的流程和文档。
