
01一个学校的调研任务
五一假期最后一天,娃不出意外的进入了疯狂补作业模式。
这时候才想起来学校布置的一项作业:调研自己姓氏的历史,起源、演变、名人、重要事件。
娃:"需要借助下科技强国的力量",然后拿走我的手机,熟练地打开了某包。
等等,不要上来就借助AI的力量,咱们先讨论下。这个作业很应景,前一段时间电视剧《太平年》很火,讲述了吴越国纳土归宋的故事,也顺带带火了"赵钱孙李"这些姓氏。
我:"为什么赵在百家姓之首?"
娃:"因为宋朝皇帝姓赵"
我:"再想想你的籍贯——我的老家在哪里?河南巩义,宋朝的皇帝都在这里埋着,我小时候还在皇帝坟头蹦过迪。再想想我们的姓"
娃惊呼:"所以我们是皇帝的..."
"不是"——我打断了他——"我们祖先来自山西洪洞县大槐树下"

永昭陵,宋仁宗的墓,以前没保护,真的在坟头上蹦过迪
言归正传——既然要做调研分析,咱们就不要用普通的联网搜索功能,今天爹地就带你体验下 DeepResearch Agent 的能力,简称 DRA。
02什么是DRA(Deep Research Agent)
传统联网问答AI拿到问题后:调用搜索引擎搜关键词,给一个概述,结束。本质上是把搜索引擎当字典查,大模型扮演的是"会说话的搜索结果摘要"。
Deep Research Agent是另一套范式:
用户给一个目标 → 模型自己规划路径 → 执行搜索 → 分析结果 → 发现缺口 → 再次搜索 → 循环直到闭环。
核心区别在于搜索在系统中扮演的角色:
传统联网问答:搜索 = 查询工具(一次性调用)
DRA:搜索 = 研究基础设施(递归调用,贯穿始终)
两者核心区别
今天我用我的小龙虾来充当RDA,我没有给他提供更多维度的关键词。只扔了一句话:
"六年级五一假期作业:研究自己姓氏(赵)的历史,起源、演变、名人、重要事件,做一份报告。"
这就是一个典型的模糊指令——没有结构,没有关键词,甚至没有明确的研究边界。
DRA拿到这句话:先规划,再行动。
小龙虾拿到指令后,先"想"了几秒钟,输出了这样一组研究框架:
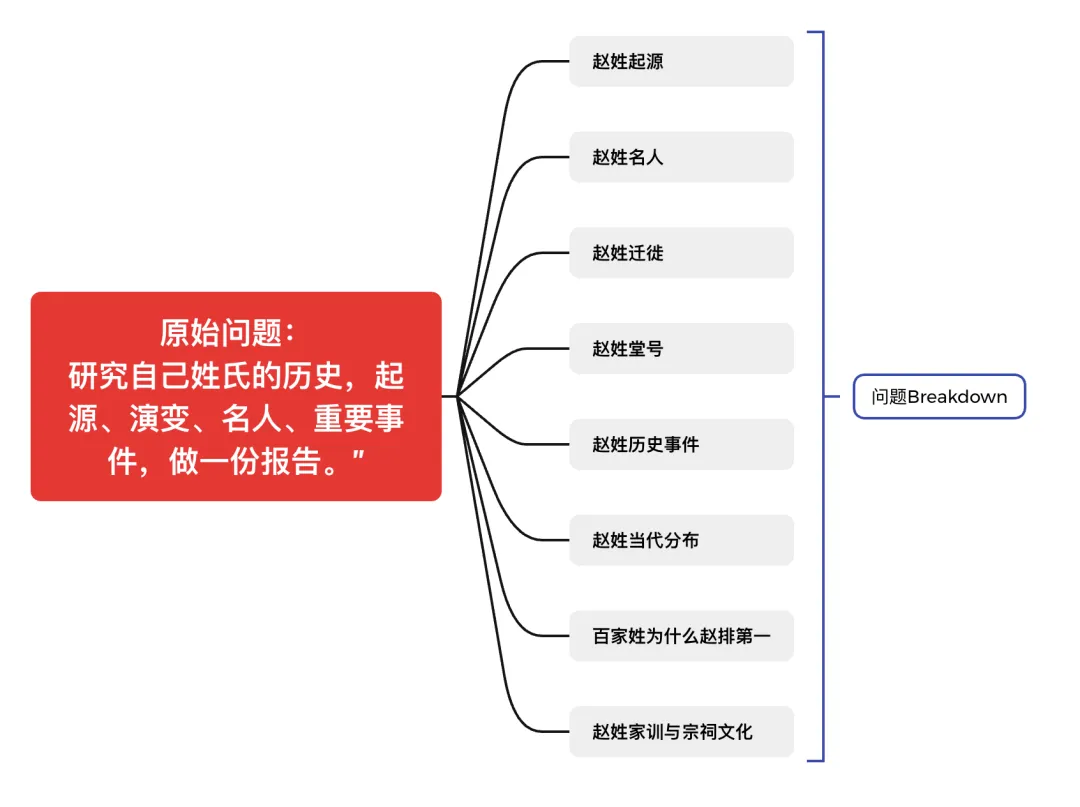
8个维度,不是我给的,是它自己规划出来的。
这才是DRA的第一步:任务分解——把一个模糊问题,拆成结构化研究框架。
03第一轮探索:先摸清楚有哪些路
有了研究框架,接下来不是一股脑全部开搜。DRA 的做法是先做一轮探索性搜索,每个维度先搜一遍,摸清楚这个方向大概有什么内容,这时小龙虾开始调用联网搜索的Skill,通过小宿的Smart Search来搜索这些内容。
比如"赵姓名人"这个维度,第一轮搜的是:
"赵姓名人 古代 现代 科技"
返回结果里,古代人物非常丰富——赵武灵王、赵云、赵匡胤、赵普、赵佶、赵孟頫……
但现代人物,几乎没有(比钱氏少多了...)。赵九章、赵元任这些现代科学文化名人,首页没有出现。
这就是 DRA 里一个非常关键的机制——在第一轮探索后,模型会反思:已获取的信息是否足以支撑结论?哪个方向的数据最薄弱?
Gap发现:"赵姓名人"中,古代分支数据丰富,现代分支数据严重不足
于是触发第二轮针对性搜索,专门补充:
"赵姓名人 现代 赵九章 赵元任"
传统 Agent:搜一遍,有结果就返回,没有就结束。
DRA:搜一遍,发现薄弱环节,主动再搜,直到这个分支闭环。
04代理化检索:搜索不是一次性的,是递归的
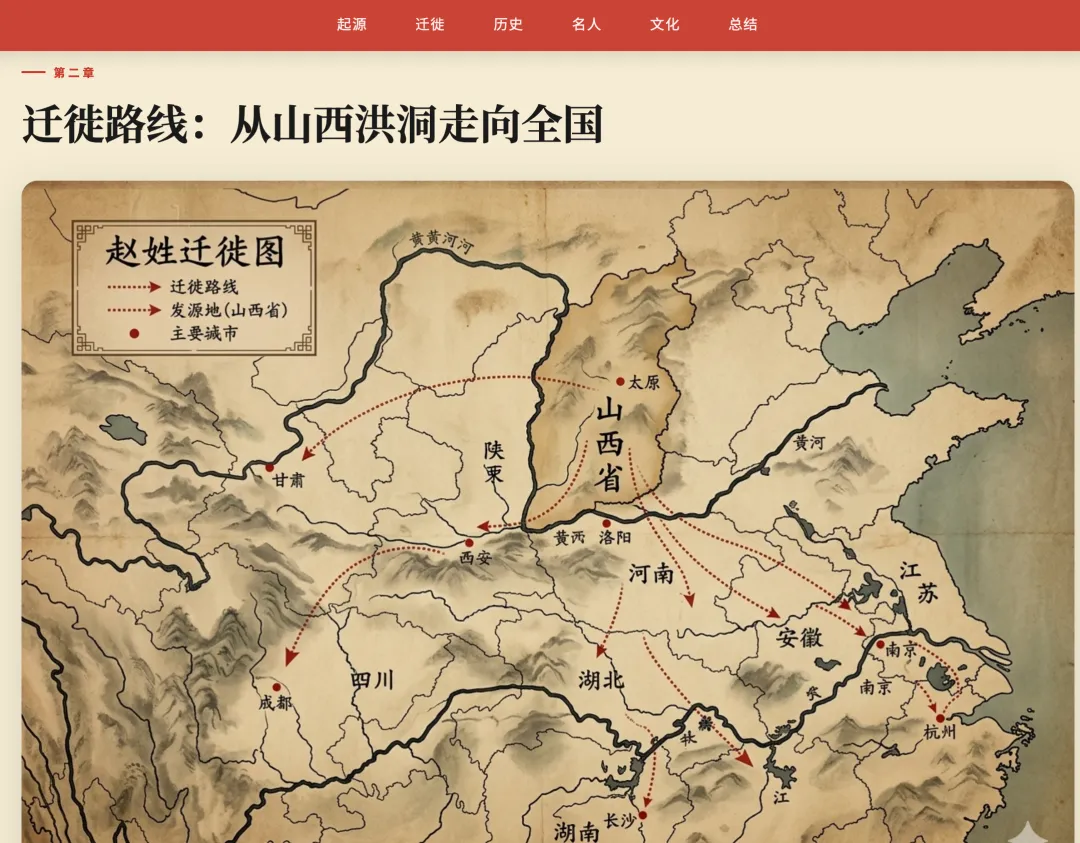
为什么DRA的搜索是"递归"的,而传统联网问答是"线性"的?用"赵姓迁徙"这个维度举例:
第一轮探索:
搜的是"赵姓迁徙路线":返回结果里开始出现三个高频节点:洪洞大槐树、靖康之变、明初移民。但此时模型对这三条线索的认知是模糊的——只知道"这些是重要节点",但不了解具体内容。
第二轮深入:
模型才针对每个节点分别深入:
"洪洞大槐树移民" → 了解了明初18次移民的政策背景和规模
"靖康之变 南宋" → 了解了北宋灭亡触发大规模南迁的完整链条
"明初移民 洪洞" → 了解了山西向全国扩散的具体路线
每一轮搜索,都会发现新的知识节点;每个新节点,都触发新一轮更精准的搜索。
这个过程不是一次性的,而是递归循环:搜→读→发现→搜→读→发现→……直到所有分支都闭环。
05上下文爆炸,和救场的参数
一开始,我用的是enableContent参数,Smart Search返回的是每篇来源的完整正文。结果触发了19次大规模搜索,每次返回10条来源,单次 JSON 动不动就几十KB,有几次破了100 KB。
实际结果:小龙虾在调研当中多次无响应,Web UI界面开始出现Compaction提示,追问后,小龙虾才会说任务因未知原因中断。毫无疑问,应该是上下文窗口撑爆了。
直到换成Chunk模式后,才恢复正常。每次只返回最相关的语义切片,JSON体积大幅缩小,管道不再堵塞,搜索链路才重新跑通。
Chunk模式:搜索引擎做预消化,而不是把全文一股脑塞进来
SmartSearch 的chunk参数,返回的是每篇来源中最相关的语义切片,而不是完整正文。把一篇万字文章切分成 3-5 个语义chunk,按相关度排序,模型直接取最相关的那几个使用。
第一步:搜索 + chunk 切分 → 每条来源直接返回最相关的语义切片
第二步:模型直接消费 chunk 切片
→ 不需要判断"要不要下钻"
→ 也不存在上下文爆炸
第三步:gap 发现 → 再次搜索
→ 再次触发 chunk 切分
→ 递归直到闭环
和full content 模式相比,chunk模式省 30%+的Token,直接从源头解决了上下文爆炸问题,不需要靠分层下钻来绕路。
没有AI Search的chunk 模式,DRA面对上下文爆炸只能采用分层下钻的方式规避——先拿摘要判断要不要下钻,再决定是否读取全文。这套流程是有效的,但增加了模型端的决策负担和调用次数。chunk模式从源头解决了这个问题。

这就是 Chunk 模式的意义。
06AI Search在DRA架构里,不只是工具,更是基础设施
从第一轮探索,到gap发现后的补充搜索,到chunk模式的按需切分——搜索这个动作,贯穿了整个DRA任务的生命周期。
这才是AI Search在DRA场景里的真正定位:不是一次性调用的插件,而是深度嵌入推理链条的核心基础设施。
并行搜索能力:多个维度同时发起搜索,节省总时间。
chunk智能切分:每条来源只返回最相关的语义切片,省 30%+ Token,直接可用。
递归调度:每次搜索结果都能触发下一轮新搜索,形成真正的搜索链路而不是单次查询。
本次实践底层用的正是小宿科技的Smart Search——chunk模式,搜索复盘如下:
总搜索次数:19次
每次返回:Top 10 条来源
理论覆盖:190条来源(含 --enable-content 全文内容)
参数模式:Chunk模式
精读页面:0次(Chunk已在返回结果中,无需二次抓取)
07最终输出:闭环之后的样子
经过三轮左右的递归搜索(探索→发现gap→补充→验证),最终拿到了完整的研究素材,并生成了调研报告:

—写在最后
传统联网问答的搜索,是"你问我答"。
DRA的搜索,是"你给我一个目标,我自己去发现还缺什么,缺什么我就再找什么"。
学校的作业是关于姓氏的。
但孩子真正看到的,是一套完整的思维方式。

