1 策略算法原理2qmt使用教程3策略算法原理4量化研报5 ptrad使用教程6 因子分析7策略算法原理

一、 核心摘要
这份由东方证券于2019年10月29日发布的研究报告,核心贡献在于系统性地构建了一套基于量价关系来度量股票买卖压力的指标体系(APB指标),并将其应用于多时间尺度的选股因子构建。研究发现,这些因子在全市场及不同样本空间中均具备显著的选股能力,且能提供与传统因子互补的增量Alpha信息。
二、 核心方法论:APB指标与买卖压力因子
理论基础:APB指标
- 定义
:报告提出了一个名为 APB(可能是Amplitude-Price-Volume Balance的缩写) 的核心指标。该指标旨在精确量化单位成交量推动价格上涨或下跌的“效率”或“压力”。 - 直观理解
:传统的价量分析可能只看“放量上涨”或“缩量下跌”。APB指标更进一步,试图回答:“同样的成交量,是推动价格上涨更多(买压强),还是导致价格下跌更多(卖压强)?” 这比简单的量价齐升/跌更能捕捉市场微观的买卖力量对比。 多时间尺度因子构建报告将APB指标应用于三个不同的时间尺度,形成了互补的因子体系:
- 月度因子
:捕捉中长期的买卖压力趋势。买压持续强的股票,可能意味着有资金在缓慢吸筹或基本面预期向好。 - 5日因子
:捕捉短期(一周左右)的买卖压力变化。适合捕捉事件驱动或短期资金流向带来的机会。 - 日内因子
:基于盘中Tick级或分钟级数据构建,捕捉极短期的交易情绪和指令流冲击。这与日间因子逻辑不同,相关性低。
三、 主要实证发现与结论
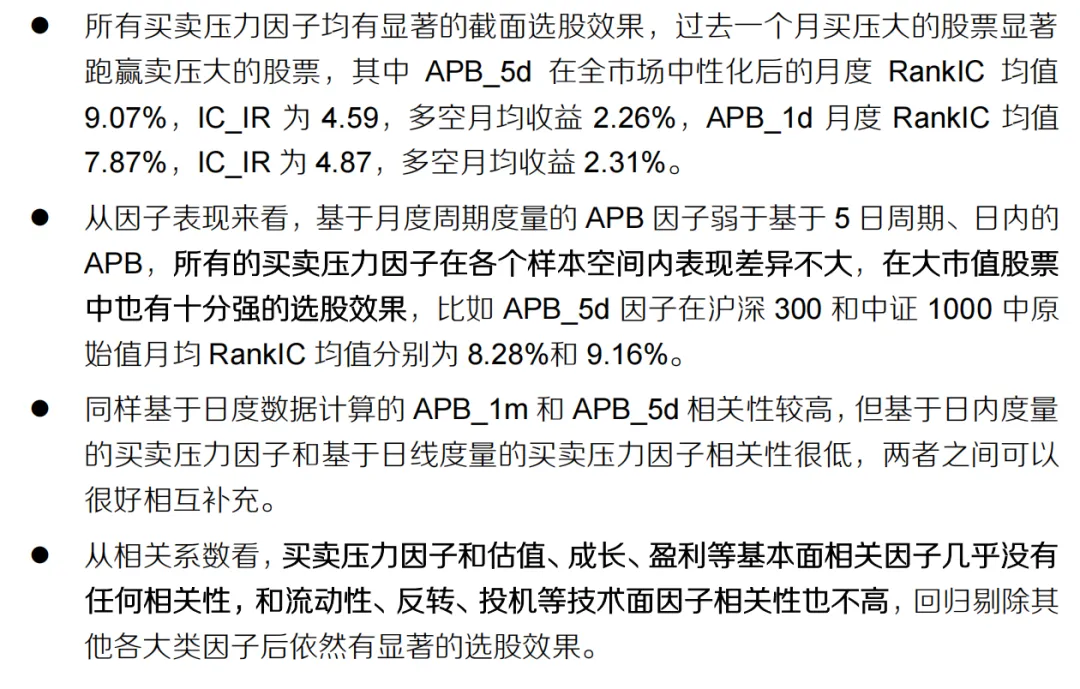
显著的截面选股能力
所有时间尺度的买卖压力因子,在全市场以及不同的样本空间(如沪深300、中证500等)内,均表现出显著的选股能力。 - 核心规律
:买压大的股票,在未来一个月显著跑赢卖压大的股票。这构成了多空策略的基础。 因子特性与互补性
- 低相关性
:报告特别指出,日内因子与日线因子(5日、月度)的相关性很低。这意味着它们捕捉的是不同维度的市场信息——日内因子更多反映瞬时交易冲击和微观结构,日线因子反映短期趋势。这种低相关性使得将它们结合使用可以提升模型的信息维度,降低风险。 - 独立性
:这些买卖压力因子与基本面因子(如估值、盈利)几乎无相关性,与多数传统技术面因子(如动量、反转)的相关性也较弱。这表明它们提供了独立的Alpha来源。 稳健性检验
- 剔除检验有效
:在回归模型中,剔除常见的市值、估值、动量、流动性等风险因子后,买卖压力因子仍然能提供显著的增量解释力。这证明了其Alpha的“纯净性”,并非只是对已有风格因子的暴露。 - 大市值股票中也有效
:通常很多量价因子在小盘股中效果更佳,但该报告指出其方法在大市值股票中同样有效,增强了策略的适用性。
四、 策略建议与应用价值
多维度Alpha捕捉:报告建议在量化选股模型中,结合使用不同时间尺度的买卖压力因子。例如,可以同时配置月度(趋势)、5日(波段)和日内(高频)因子,形成一个能够同时捕捉长、中、短期资金动向的复合信号,从而提升策略的稳定性和收益来源的多样性。
作为传统模型的补充:由于与基本面因子相关性弱,该体系可以作为传统多因子模型(侧重基本面、估值)的有力补充,构建“基本面+市场行为”的混合模型,以应对不同市场环境。
五、 风险提示与局限
报告也客观地指出了应用时需要注意的风险,这与知识库中其他研报的共识一致:
- 模型失效风险
:任何基于历史数据规律的量化模型都可能在未来失效,需要紧密跟踪其表现。 - 极端市场环境冲击
:在系统性风险、市场流动性枯竭或监管政策突变等极端情况下,量价关系可能失真,因子效果会大打折扣。 - 数据与计算要求
:尤其是日内因子的构建,对高频数据的质量和计算能力有一定要求。
六、 在知识库中的定位与比较
将此报告置于您提供的整个知识库背景下,可以看出其独特价值和关联:
- 与海通证券“量价结合”因子(2016)
:海通报告侧重于用“量价相关性”区分背离与同向,本质也是量价关系分析。东方证券的APB指标可能是一种更精细、更直接的“压力”度量方式,且系统化了多时间尺度应用。 - 与“潮汐”因子(2022)
:两者都利用成交量模式。“潮汐”因子关注成交量“由低到高再回落”的完整形态,而APB更关注成交量与价格变动的“效率比”,视角不同。 - 与国盛证券“日间量价模型”(2019)
:国盛报告强调高频、高换手、低容量的T+1策略体系。东方证券的框架则涵盖了从日内到月度的多种频率,提供了将高频逻辑降频应用于中低频策略的一种思路,可能具有更大的策略容量。 - 与天风证券“订单簿上的alpha”(2019)
:天风报告从更微观的订单簿数据中提取信息。东方证券本报告主要基于已成交的价量数据,数据源更普遍,但逻辑上同样致力于挖掘交易行为背后的信息。
总结
这份东方证券的报告是一份逻辑清晰、实证扎实、实用性强的优秀量价因子研究。它没有停留在简单的价量结合,而是创新性地提出了“买卖压力”的量化思想,并通过多时间尺度分解,构建了一个立体化的因子体系。其核心亮点在于证明了日内与日间价量信息低相关且可互补,这为构建更加鲁棒的多因子选股模型提供了宝贵的思路。对于量化研究者而言,其方法论(APB指标构建、多尺度分析、严谨的稳健性检验)具有很高的借鉴价值。
# -*- coding: utf-8 -*-"""东方证券APB买卖压力因子计算参考:东方证券《因子选股系列研究六十:基于量价关系度量股票的买卖压力》核心指标:APB = log(等权加权均价 / 成交量加权均价)三个时间尺度:APB_1m: 月度周期计算APB_5d: 基于过去5个交易日滚动计算,过去1个月求均值APB_1d: 基于日内5分钟K线计算,过去1个月求均值"""import numpy as npimport pandas as pdfrom datetime import datetime, timedeltaimport warningswarnings.filterwarnings('ignore')# ==================== 第一部分:数据准备(模拟数据) ====================def generate_sample_data(start_date='2025-01-01', end_date='2025-03-31', n_stocks=100):"""生成模拟的股票日频和分钟频数据,用于演示APB因子计算。实战中应替换为真实的行情数据(如来自Wind、Tushare等)。"""np.random.seed(42)# 生成交易日序列all_dates = pd.date_range(start_date, end_date, freq='B')stock_codes = [f'STK{i:03d}' for i in range(n_stocks)]# ---------- 日频数据生成 ----------daily_data = []for date in all_dates:for code in stock_codes:# 模拟基础价格(假设服从随机游走)base_price = 10 + np.random.randn() * 2# 模拟日频VWAP(成交量加权平均价)和成交量vwap_daily = base_price * (1 + np.random.randn() * 0.02)volume_daily = np.random.lognormal(12, 1.5) # 成交量daily_data.append({'date': date,'code': code,'vwap': vwap_daily,'volume': volume_daily})df_daily = pd.DataFrame(daily_data)# ---------- 分钟频数据生成(用于APB_1d) ----------# 假设每天有240分钟(4小时交易)minute_data = []for date in all_dates:for code in stock_codes:# 生成日内分钟价格序列(假设有趋势和波动)intraday_trend = np.linspace(-0.01, 0.01, 240)intraday_noise = np.random.randn(240) * 0.005minute_prices = 10 * (1 + intraday_trend + intraday_noise)# 生成分钟成交量(通常有U形分布)time_index = np.arange(240)volume_pattern = 0.5 + 0.5 * np.sin(2 * np.pi * time_index / 240 - np.pi/2) # U形minute_volumes = np.random.lognormal(8, 1) * volume_patternfor t in range(240):minute_data.append({'datetime': date + timedelta(minutes=t),'date': date,'code': code,'price': minute_prices[t],'volume': minute_volumes[t]})df_minute = pd.DataFrame(minute_data)return df_daily, df_minute# ==================== 第二部分:核心APB指标计算函数 ====================def calculate_apb(vwap_array, volume_array):"""计算单周期APB指标APB = log(等权加权均价 / 成交量加权均价)参数:vwap_array: 数组,某周期内各时间点的VWAP价格volume_array: 数组,对应时间点的成交量返回:apb值 (float)"""# 等权加权均价(算术平均)equal_weighted_avg = np.mean(vwap_array)# 成交量加权均价(VWAP of the period)if np.sum(volume_array) > 0:volume_weighted_avg = np.sum(vwap_array * volume_array) / np.sum(volume_array)else:volume_weighted_avg = equal_weighted_avg# 避免除零或负数if volume_weighted_avg <= 0:return 0.0# 计算APB(取对数)apb = np.log(equal_weighted_avg / volume_weighted_avg)return apb# ==================== 第三部分:三个时间尺度APB因子计算 ====================def calculate_apb_1m(df_daily, lookback_month=1):"""计算月度APB因子 (APB_1m)步骤:1. 对每只股票,按月计算APB(使用当月所有交易日的vwap和volume)2. 将月度APB值赋给该月最后一个交易日"""df = df_daily.copy()df['year_month'] = df['date'].dt.to_period('M')# 按股票和月份分组计算APBdef calc_monthly_apb(group):if len(group) < 5: # 至少需要5个交易日return np.nanreturn calculate_apb(group['vwap'].values, group['volume'].values)monthly_apb = df.groupby(['code', 'year_month']).apply(calc_monthly_apb)monthly_apb = monthly_apb.reset_index(name='apb_1m_raw')# 找到每月的最后一个交易日last_dates = df.groupby(['code', 'year_month'])['date'].max().reset_index()monthly_data = pd.merge(last_dates, monthly_apb, on=['code', 'year_month'])# 合并回原始数据(向前填充,直到下一个月度值出现)df_result = pd.merge(df, monthly_data[['code', 'date', 'apb_1m_raw']],on=['code', 'date'], how='left')df_result['apb_1m_raw'] = df_result.groupby('code')['apb_1m_raw'].ffill()# 过去N个月均值(研报中是过去1个月,这里lookback_month可调)df_result['apb_1m'] = df_result.groupby('code')['apb_1m_raw'].rolling(window=lookback_month, min_periods=1).mean().reset_index(level=0, drop=True)return df_resultdef calculate_apb_5d(df_daily, lookback_days=5, smooth_window=20):"""计算5日滚动APB因子 (APB_5d)步骤:1. 对每只股票,滚动计算过去5个交易日的APB2. 对APB序列取过去1个月(约20个交易日)的均值"""df = df_daily.copy()# 按股票分组,滚动计算5日APBdef rolling_5d_apb(stock_df):vwap = stock_df['vwap'].valuesvolume = stock_df['volume'].valuesdates = stock_df['date'].valuesapb_5d_raw = np.full(len(stock_df), np.nan)for i in range(lookback_days-1, len(stock_df)):start_idx = i - lookback_days + 1vwap_window = vwap[start_idx:i+1]volume_window = volume[start_idx:i+1]if len(vwap_window) == lookback_days:apb_5d_raw[i] = calculate_apb(vwap_window, volume_window)return apb_5d_rawdf['apb_5d_raw'] = df.groupby('code', group_keys=False).apply(lambda x: pd.Series(rolling_5d_apb(x), index=x.index))# 过去1个月平滑(约20个交易日)df['apb_5d'] = df.groupby('code')['apb_5d_raw'].rolling(window=smooth_window, min_periods=1).mean().reset_index(level=0, drop=True)return dfdef calculate_apb_1d(df_daily, df_minute, smooth_window=20):"""计算日内APB因子 (APB_1d)步骤:1. 对每只股票每个交易日,基于日内分钟数据计算APB2. 对日度APB序列取过去1个月(约20个交易日)的均值"""# 从分钟数据计算每日的日内APBdef calc_daily_intraday_apb(date_group):if len(date_group) < 10: # 至少需要一定数量的分钟数据return np.nan# 使用分钟级的price和volume计算APBreturn calculate_apb(date_group['price'].values, date_group['volume'].values)# 计算每只股票每天的日内APBdaily_apb = df_minute.groupby(['code', 'date']).apply(calc_daily_intraday_apb)daily_apb = daily_apb.reset_index(name='apb_1d_daily')# 合并到日频数据df = df_daily.copy()df = pd.merge(df, daily_apb, on=['code', 'date'], how='left')# 过去1个月平滑(约20个交易日)df['apb_1d'] = df.groupby('code')['apb_1d_daily'].rolling(window=smooth_window, min_periods=1).mean().reset_index(level=0, drop=True)return df# ==================== 第四部分:因子合并与中性化处理 ====================def merge_all_factors(df_1m, df_5d, df_1d):"""合并三个时间尺度的APB因子到一个DataFrame"""# 提取需要的列factors_1m = df_1m[['date', 'code', 'apb_1m']].copy()factors_5d = df_5d[['date', 'code', 'apb_5d']].copy()factors_1d = df_1d[['date', 'code', 'apb_1d']].copy()# 合并merged = pd.merge(factors_1m, factors_5d, on=['date', 'code'], how='outer')merged = pd.merge(merged, factors_1d, on=['date', 'code'], how='outer')return mergeddef neutralize_factors(df_factors, df_industry_market_cap):"""对因子进行行业市值中性化处理(如研报中所做)参数:df_factors: 包含因子的DataFramedf_industry_market_cap: 包含行业和市值信息的DataFrame返回:中性化后的因子DataFrame"""# 这里简化处理:假设我们已经有了行业和市值数据# 实际应用中需要从外部获取df = pd.merge(df_factors, df_industry_market_cap, on=['date', 'code'], how='left')neutralized_factors = df_factors.copy()for factor_col in ['apb_1m', 'apb_5d', 'apb_1d']:if factor_col in df.columns:# 按日期进行横截面回归,残差作为中性化因子neutralized_col = f'{factor_col}_neutral'neutralized_factors[neutralized_col] = np.nanfor date, group in df.groupby('date'):if factor_col in group.columns and 'industry' in group.columns and 'market_cap' in group.columns:# 简单示例:先对行业取哑变量,再对市值回归# 实际应使用更严谨的方法industry_dummies = pd.get_dummies(group['industry'], prefix='ind')X = pd.concat([industry_dummies, group['market_cap'].values.reshape(-1, 1)], axis=1)y = group[factor_col].valuesif len(y) > X.shape[1] + 5: # 足够样本from sklearn.linear_model import LinearRegressionmodel = LinearRegression()model.fit(X.fillna(0), y)residuals = y - model.predict(X.fillna(0))# 标准化残差if np.std(residuals) > 0:residuals = (residuals - np.mean(residuals)) / np.std(residuals)idx = group.indexneutralized_factors.loc[idx, neutralized_col] = residualsreturn neutralized_factors# ==================== 第五部分:主执行流程 ====================def main():print("=" * 80)print("东方证券APB买卖压力因子计算")print("=" * 80)# 1. 生成模拟数据print("\n[1/4] 生成模拟数据...")df_daily, df_minute = generate_sample_data(start_date='2025-01-01',end_date='2025-03-31',n_stocks=50)print(f"日频数据形状: {df_daily.shape}")print(f"分钟数据形状: {df_minute.shape}")print(f"时间范围: {df_daily['date'].min()} 到 {df_daily['date'].max()}")print(f"股票数量: {df_daily['code'].nunique()}")# 2. 计算三个时间尺度的APB因子print("\n[2/4] 计算APB_1m(月度因子)...")df_apb_1m = calculate_apb_1m(df_daily, lookback_month=1)print("计算APB_5d(5日滚动因子)...")df_apb_5d = calculate_apb_5d(df_daily, lookback_days=5, smooth_window=20)print("计算APB_1d(日内因子)...")df_apb_1d = calculate_apb_1d(df_daily, df_minute, smooth_window=20)# 3. 合并因子print("\n[3/4] 合并所有因子...")df_factors = merge_all_factors(df_apb_1m, df_apb_5d, df_apb_1d)# 显示示例print("\n因子数据示例(前5行):")print(df_factors.head())# 4. 基本统计分析(模拟研报中的分析)print("\n[4/4] 因子基本统计分析...")# 因子描述性统计print("\n因子描述性统计:")stats = df_factors[['apb_1m', 'apb_5d', 'apb_1d']].describe()print(stats)# 因子间相关性(模拟研报表3.2)print("\n因子间相关系数(Spearman秩相关):")corr_matrix = df_factors[['apb_1m', 'apb_5d', 'apb_1d']].corr(method='spearman')print(corr_matrix)# 检查因子分布(模拟研报图2)print("\n因子值小于0的比例(类似处置效应检查):")for col in ['apb_1m', 'apb_5d', 'apb_1d']:if col in df_factors.columns:pct_negative = (df_factors[col] < 0).mean() * 100print(f"{col}: {pct_negative:.1f}% 的值为负")# 因子时间序列示例(取一只股票)sample_stock = df_factors['code'].ilocsample_data = df_factors[df_factors['code'] == sample_stock].sort_values('date')print(f"\n示例股票 {sample_stock} 的因子时间序列(前10个交易日):")print(sample_data[['date', 'apb_1m', 'apb_5d', 'apb_1d']].head(10))return df_factors, df_daily, df_minute# ==================== 执行主函数 ====================if __name__ == "__main__":# 运行完整计算流程df_factors, df_daily, df_minute = main()# 提供后续分析建议print("\n" + "=" * 80)print("后续分析建议")print("=" * 80)print("""# 1. 因子选股能力回测(模拟研报第2章)# 需要准备未来收益率数据# future_ret = df_daily.groupby('code')['vwap'].pct_change().shift(-1) # 示例# 2. 因子分组收益(模拟研报图4-6)def factor_group_backtest(factor_values, future_returns, n_groups=10):\"\"\"因子十分组回测\"\"\"groups = pd.qcut(factor_values, q=n_groups, labels=False, duplicates='drop')group_returns = future_returns.groupby(groups).mean()return group_returns# 3. 因子IC分析(模拟研报表2.2)def calculate_rank_ic(factor_series, ret_series):\"\"\"计算Rank IC\"\"\"from scipy.stats import spearmanrvalid_mask = ~factor_series.isna() & ~ret_series.isna()if sum(valid_mask) > 10:ic, _ = spearmanr(factor_series[valid_mask], ret_series[valid_mask])return icreturn np.nan# 4. 因子中性化(模拟研报第3章)# 需要行业和市值数据# df_neutral = neutralize_factors(df_factors, df_industry_market_cap)""")