

2025年北京亦庄,二十余款人形机器人在半程马拉松赛场上跌跌撞撞:摔倒、漂移、被人搀扶,姿态虽笨拙,却标志着机器人正迈出实验室,走向真实世界。
2026年的春晚舞台各大厂商的人形机器人踩着节拍,整齐完成打太极、翻跟头等动作,引发观众热议。
作为北京大学学生人工智能创新会,我们紧跟具身智能前沿,围绕其核心技术体系与产业落地逻辑展开系统性研究。具身智能系列报告将从VLA、世界模型、数据采集、机器人硬件四大板块,全方位拆解技术内核、发展瓶颈与落地前景。
本次发布的研报聚焦VLA板块。VLA作为具身智能核心范式之一,是机器人实现“感知-理解-行动”一体化的关键路径。我们将拆解其架构机理与技术瓶颈,客观评估它距离“真正能用”还有几步,以及分析2026年哪些关键变量将决定其边界。
本文为研报预览,完整深度分析、技术细节与行业研判,请点击文末【阅读原文】。
引言
VLA(视觉-语言-动作)模型将机器视觉与语言指令融合,通过端到端架构直接输出物理动作,彻底打破传统“感知-建图-规划-控制”的流程,显著提升系统响应效率。其动作表征涵盖从高层语义指令到底层连续控制信号的完整谱系,表征粒度越精细,动作执行越灵巧,但训练难度亦呈指数级攀升。与仅能生成行动文本的视觉语言模型(VLM)不同,VLA的核心突破在于直接输出驱动电机的物理控制信号。该模型按能力可分为四个递进层级,随着任务复杂度与泛化能力逐级提升,逐步迈向通用具身智能的终极目标。
一、核心架构与实现机理
(图片来源:AI辅助生成)
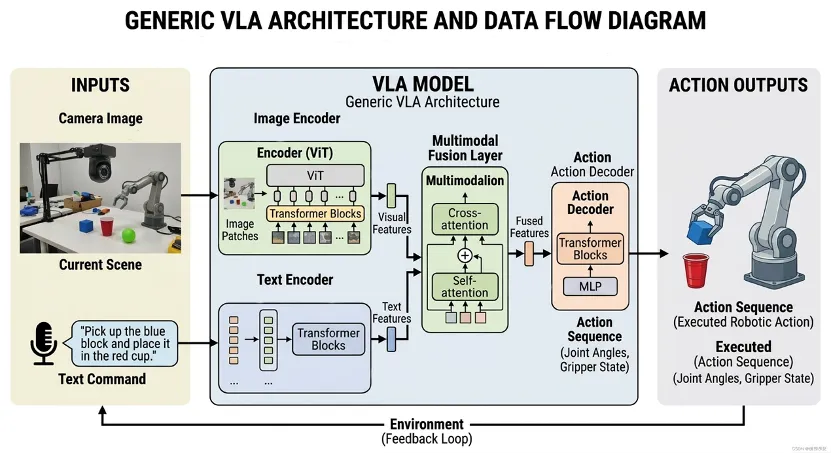
VLA(视觉-语言-动作)模型,目前是具身智能领域的核心范式之一。与传统机器人依赖“感知—规划—控制”多模块流水线不同,VLA通过端到端模型,直接将视觉信息与语言指令映射为具体动作,实现从“看懂世界”到“改变世界”的一体化决策。这一变化不仅大幅提升响应效率,也让机器人具备更接近人类的感知与执行能力。但关键差异在于:VLA不仅“会理解”,更“能动手”。如果一个模型只能描述“如何抓苹果”,却无法驱动机械臂去完成动作,那它仍停留在视觉语言模型(VLM)阶段;只有真正输出物理控制信号,才能跨入VLA的门槛。从能力演进来看,VLA正经历从简单指令执行到复杂开放任务的跃迁:早期系统只能完成单一步骤抓取,中期可组合技能完成流程任务,而最新模型已开始探索连续动作生成与长时程自主决策。然而,随着能力提升,泛化能力不足、环境扰动敏感以及长程记忆缺失等问题也逐渐显现。正是在这种“能力突破与现实瓶颈并存”的阶段,VLA成为当前最值得关注的技术方向之一。
VLA的核心架构,本质上可以拆解为三个关键环节:看懂世界、做出决策、稳定执行。首先,在感知层,VLA需要将摄像头等传感器获取的非结构化信息编码为可计算表征,并完成视觉、语言与空间信息的对齐。相比传统以2D识别为主的方式,当前技术正从“看是什么”升级到“理解三维空间关系”,通过引入深度、点云等3D信息,让机器人不仅知道物体类别,还能判断位置、姿态和可操作性。同时,语言不再只是描述任务,而是直接参与注意力分配与决策约束,真正实现“用语言指挥动作”。
在决策层,VLA需要将多模态信息转化为具体动作,但现实世界往往存在多种可行解,因此模型既要精确控制,又要具备多样性表达能力。目前主流方法分为两类:一类是类似语言模型的自回归方式,逐步生成动作序列,适合长任务规划;另一类是生成整段连续轨迹的分布模型(如扩散策略),更适用于精细操作与复杂交互。实际系统往往采用两者结合,以兼顾稳定性与灵活性。
在执行层,工程挑战在于“模型推理慢、机器人控制快”的矛盾。通过分层架构可以一定程度上解决这个问题:上层VLA负责低频决策,下层控制器负责高频执行,并通过“动作分块+滚动重规划”持续纠偏。同时,引入安全过滤机制,确保动作在可达、无碰撞的安全范围内。
整体来看,VLA的关键不只是模型规模,而在于如何在感知、决策与控制之间实现高效协同,从而让机器人真正具备稳定、可部署的行动能力。
二、VLA训练范式
VLA的训练,本质上是把“互联网知识”和“真实世界操作经验”融合在一起,让模型既会理解,也能行动。当前主流架构采用“两阶段”路径:首先通过大规模视觉语言模型(VLM)进行预训练,让模型学会识别物体、理解指令;随后再引入机器人轨迹数据进行后训练,将语义理解映射为具体动作,实现从“看懂”到“做出”的闭环。这种将动作离散化为token、统一为序列生成的问题设定,使VLA能够直接复用大模型的能力,成为当前最主流的实现方式。
在具体方法上,VLA训练主要依赖三类范式。第一是监督学习,尤其是模仿学习,通过专家演示数据学习“看到什么就做什么”,简单高效,是当前大规模训练的核心手段;第二是自监督学习,用于提升视觉表示和跨模态对齐能力,并在缺乏标注数据时挖掘潜在结构;第三是强化学习,通过与环境交互,让模型在真实或模拟环境中不断优化策略,从而提升泛化能力和闭环控制能力。
在实际系统中,这三种方法往往是融合使用的:模仿学习提供稳定起点,自监督学习增强表示能力,强化学习则负责在真实环境中“打磨”策略。当前的发展趋势也逐渐清晰——从单一训练方式走向混合范式,通过世界模型、数字孪生和仿真-现实迁移等技术,提升样本效率与安全性。未来,VLA的关键不再只是“学得多”,而是如何在有限数据和复杂环境中,实现稳定、可泛化的真实世界执行能力。
三、VLA模型核心技术挑战、应对路径与发展趋势
当前,VLA正从实验室走向真实世界应用,但也正面临三大核心瓶颈。首先是泛化能力不足:模型高度依赖训练数据分布,在跨任务、跨环境甚至跨硬件场景下表现明显下降。例如,仿真环境与真实世界之间仍存在显著差距,光照变化、材质差异或触觉反馈缺失都可能导致系统失效;同时,不同机器人之间的结构差异也使“一套模型适配多设备”仍具挑战。
其次是工业级可靠性问题。在长时任务中,微小误差会逐步累积,导致策略漂移;而大模型推理延迟(通常达100–300ms)难以满足实时控制需求。此外,VLA本质上是概率模型,其输出存在不确定性,这与工业场景“零容错”的安全要求之间存在根本冲突。因此,当前主流方案逐渐转向“云端大脑+端侧小脑”的分层架构,在性能与实时性之间寻求平衡。
最后是评测体系的缺失与碎片化。现有基准多基于特定仿真环境或硬件平台,缺乏统一标准,导致不同模型难以公平比较。同时,单次任务成功率难以反映真实应用价值,行业开始关注如MPI(平均干预间隔)等更贴近实际场景的指标。整体来看,评价体系的不统一正成为制约VLA规模化落地的重要非技术障碍。
面对泛化能力、工程性能与评测体系三大瓶颈,VLA正在进入从“技术可行”迈向“工业可用”的关键阶段。首先,在泛化能力上,研究正从简单的数据拟合转向结构化理解:通过构建“原子技能库”实现组合泛化,引入世界模型进行动作预演以弥合仿真与现实差距,并通过动作空间归一化推动跨硬件统一控制,使模型具备更强的跨任务、跨环境与跨设备能力。
其次,在性能优化方面,行业逐渐形成“类人双系统”架构:低频的高层模型负责规划与推理,高频控制模块负责实时执行,从而解决大模型推理慢与机器人控制快之间的矛盾。同时,动作分块与时延压缩技术的引入,使端到端模型开始接近工业级实时性要求。
在评测体系上,评价标准也正在从“单次成功率”转向更贴近真实应用的指标,如平均干预间隔(MPI)以及动态环境下的闭环测试,强调系统在连续任务中的稳定性与鲁棒性。
从产业格局来看,当前已形成端到端、混合架构、垂直整合与开源生态四条技术路线,并逐渐走向融合。值得注意的是,VLA范式最早已在自动驾驶中得到验证,机器人只是下一阶段的规模化落地场景。未来几年,工业制造仍将是最先实现规模应用的领域,而消费级场景则仍需等待技术成熟与安全标准的进一步完善。

北大学生人工智能创新会,简称PKU SAIIC,是北大校内唯一的人工智能社团,由校团委,计算机学院团委、人工智能创新中心共同领导,施柏鑫老师指导。
研报作者:李盈皞、晋禹超、罗著、陈婉昱
系列研报发起与统筹:Valeri
研报顾问:王思涵、余振葳
本篇研报统筹:李盈皞、罗著
审核:施老师、于老师、Valeri、王鹏翔
排版:Claire

