
作者|Maxim Massenkoff、Eva Lyubich、Peter McCrory、Ruth Appel、Ryan Heller|2026 年 3 月 24 日
Anthropic Economic Index(经济指数)依托一套保护隐私的数据分析系统,追踪 Claude 在整个经济中的使用情况。这项工作的目标,是尽可能提前理解 AI 对经济的影响,好让研究者和政策制定者有更充足的准备时间。
这份最新报告分析的是 2026 年 2 月 Claude 的使用情况,并延续了上一篇报告提出的“经济基本单元”框架。上一篇报告使用的是 2025 年 11 月的数据。本次样本覆盖 2026 年 2 月 5 日至 12 日,这个时间点距离 Claude Opus 4.5 发布约三个月,也与 Claude Opus 4.6 的发布大致重合。
首先,我们梳理了 Claude 的使用方式相较前几份报告发生了哪些变化:在 Claude.ai 和 API 流量中,增强型使用(也就是 AI 以协作方式补足用户能力的场景)都略有上升。在 Claude.ai 上,用途进一步分散,前 10 大任务在上个月所占的使用份额低于 2025 年 11 月。随着这种分散化,Claude.ai 上单次对话所对应任务的平均工资水平也比前几份报告略低。
接着,我们把重点放在一个会显著影响 Claude 对劳动力市场乃至更广泛经济影响的因素上:用户在采用 Claude 过程中的学习曲线。我们的证据表明,使用时长更长的用户已经形成了一些习惯和策略,使他们更擅长发挥 Claude 的能力。换句话说,更有经验的用户不仅会尝试价值更高的任务,也更容易从对话中获得成功的结果。
自上一篇报告以来,有什么变化
在第一章中,我们回顾了上一篇《Anthropic Economic Index report》(发表于 2026 年 1 月)中的主要结论。我们的新发现包括:
Claude.ai 上的使用场景进一步分散。编码任务继续从 Claude.ai 上的增强型使用,迁移到第一方 API 中更自动化的工作流。到 2026 年 2 月,Claude.ai 的使用已经没有 2025 年 11 月那么集中(1):最常见的前 10 个任务只占全部流量的 19%,而此前是 24%。不过,在这次样本里,几乎所有任务都至少在我们之前的某次样本中出现过。大约 49% 的工作岗位,已经有至少四分之一的任务会借助 Claude 完成。 Claude 的采用扩展到了工资更低的任务。随着用例进一步分散,Claude 所执行工作的平均经济价值,也就是对应职业在美国劳动力市场上的工资水平,略有下降。直接原因是,围绕体育、商品比较和家庭维护等个人问题的查询变多了。这符合典型的“采用曲线”逻辑:早期采用者更偏好编码这类高价值、边界清晰的用法;随着用户群扩大,AI 承担的任务种类也会迅速变宽。 全球使用率不平均依然存在。按人均口径计算,前 20 个国家占了总使用量的 48%,高于此前的 45%,说明全球采用差距仍未缩小。不过,在美国内部,Claude 的人均使用量还在继续收敛:使用量最高的 10 个州,其占比已从 40% 降到 38%。
学习曲线
经济指数中的一个核心发现是:Claude 的早期采用极不均衡。Claude 在高收入国家用得更密集;在美国内部,则更多集中在知识工作者更密集的地区;同时,它也主要集中在相对少数、较为专业的任务和职业上。
一个关键问题是,这种采用上的不平等,会如何决定 AI 的收益最终流向哪里、又流向哪些人。比如,如果高效使用 AI 需要一些互补技能和专业能力(这也是我们在上一篇报告里提出的判断)而这些能力又可以通过使用和试验逐步获得,那么早期采用带来的收益就可能会自我强化(指一个过程因自身结果而被持续加强,而非趋于平衡)。
在第二章中,我们考察了用户似乎是如何塑造自己从 Claude 身上获得的价值的:他们如何让模型能力与当前任务相匹配,以及使用模式和结果会如何随着平台使用经验的积累而变化。
模型选择会随着任务而变化。我们发现,用户会把最强的模型类别 Opus,更多地用在那些在劳动力市场上通常对应更高工资的任务上。比如,在付费 Claude.ai 用户中,Opus 在编码任务上的使用率比平均水平高 4 个百分点,而在辅导类任务上的使用率则低 7 个百分点。对于 API 用户,这种模型切换更明显,强度大约是前者的两倍。
使用时长更长,成功率也更高。总体来看,最资深的 Claude 用户更常把它用在需要更高教育水平的任务上,也更少用于个人场景。举例来说,使用 Claude 满 6 个月或更久的人,个人对话会少 10%,而他们输入中体现出来的教育水平则高出 6%。更值得注意的是,这个高使用时长群体在对话中的成功率高出 10%,而这种关联并不能用任务选择、所在国家或其他简单因素来解释。它当然可能反映了早期采用者本身更成熟,但也可能是“边用边学”的证据:人们会随着经验累积而越来越擅长使用 Claude。
自上一篇报告以来,有什么变化
Claude.ai 用例的多样化
先来看 Claude 被拿来做什么。我们使用那套保护隐私的系统,只在聚合层面分析行为,而不触及任何单条对话内容。样本来自两部分:面向消费者的 Web 产品 Claude.ai,以及面向开发者、可将 Claude 集成进产品和工作流的第一方 API;两边各抽取了 100 万段对话。(2)
编码仍然是平台上最常见的使用方式。与计算机和数学类职业相关的任务,占到了 Claude.ai 对话的 35%(更完整的职业类别占比见附录)。(3) 不过,在 2025 年 11 月到 2026 年 2 月之间,Claude.ai 上的用例明显变得没那么集中:最常见的 10 个 O*NET 任务,占对话总量的比例从 24% 降到了 19%(图 1.1)。
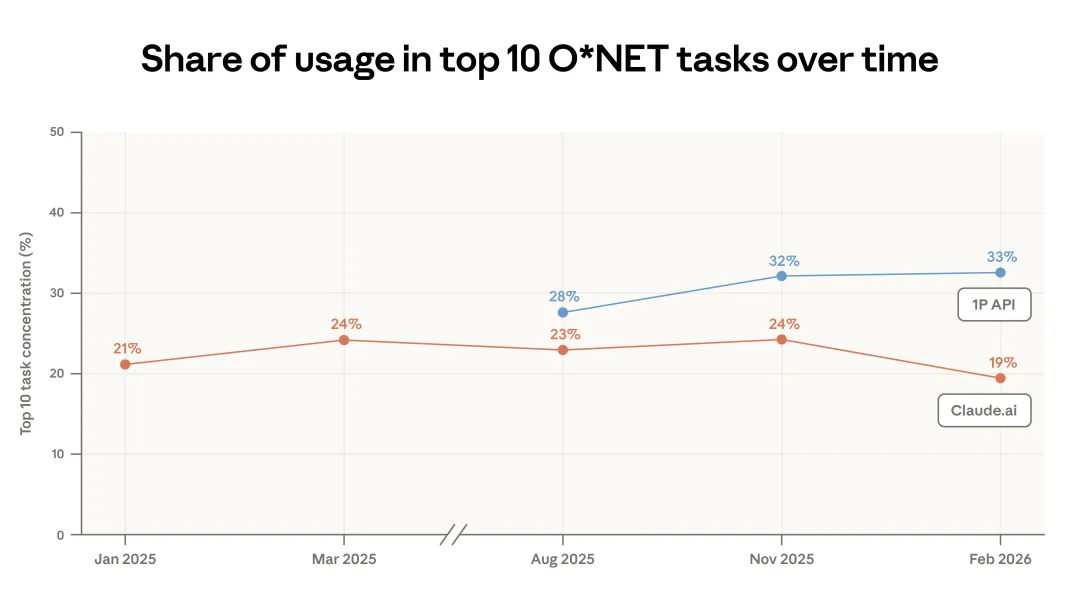
图 1.1:按平台统计的前 10 个任务使用占比变化。展示 Claude.ai 与第一方 API 中,最常见 10 个 O*NET 任务在各期报告中的对话占比。
这种集中度下降,一部分是因为编码任务正在从 Claude.ai 转向第一方 API。在 API 样本里,Claude Code 已经占了相当大的份额。由于 Claude Code 的 agentic 架构会把编码工作拆成更小的 API 调用,而这些调用又会被标注为不同任务,所以虽然编码在 API 流量中的总体占比提高了,但它被分散到了更多任务类别里,不再集中在少数几个类别上。
因此,尽管编码活动大量涌入,API 端的任务集中度整体上基本没有变化。
代码从 Claude.ai 迁出,并不是集中度下降的唯一原因。这一下降还有一部分来自两个时期之间用例结构的变化:课程作业类用途从全部对话的 19% 降到了 12%,而个人用途则从 35% 升到了 42%。课程作业类用途的下滑,有一部分可以用学期安排来解释:在我们的抽样期间,一些国家的学生正处于寒假。(4)同时,2 月前后注册人数增加,也带来了更多更休闲的 AI 用户。
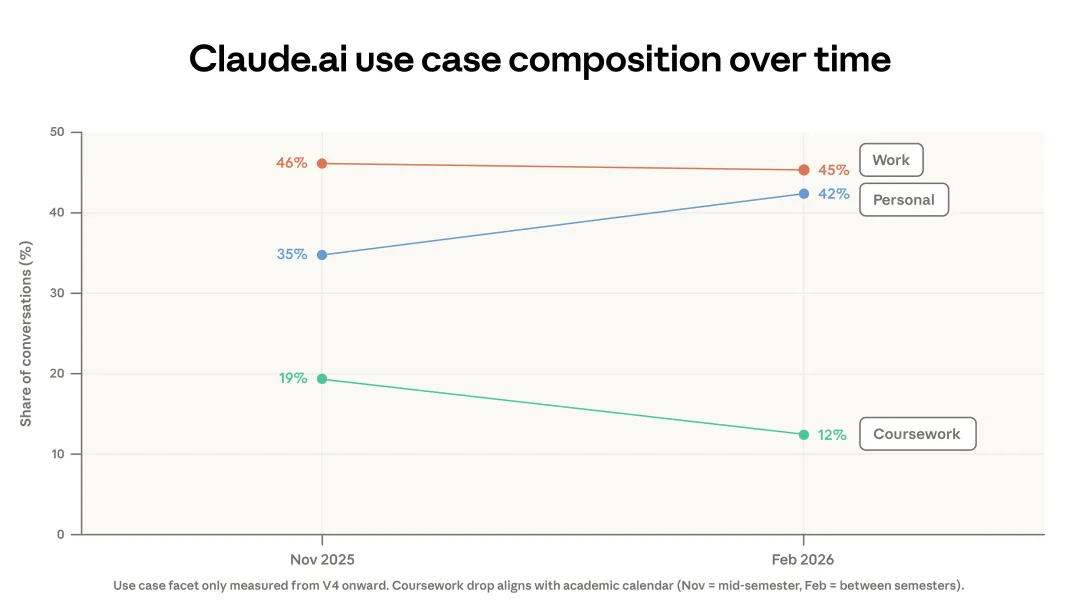
图 1.2:Claude.ai 上工作、个人与课程作业用途的变化。展示 2025 年 11 月与 2026 年 2 月两期样本中,三类对话所占比例。
虽然 Claude 处理的工作类任务变得更多样,但这些任务几乎都不是第一次出现。上一篇报告里我们提到,49% 的岗位已经有至少四分之一的任务借助 Claude 完成;在这次数据里,这个累计估计几乎没变(见附录图 A.2)。与上一篇相比,这次新增的 O*NET 任务也少得多。
自第一份报告以来,我们把对话分成了五种互动类型:指令式、反馈回路、任务迭代、验证和学习;再把它们归成两大类:自动化与增强型使用。(5) 图 1.3 显示,Claude.ai 上的增强型使用略有增加,主要来自验证和学习模式的小幅上升。而在附录图 A.3 中,我们展示了第一方 API 数据里的自动化明显下降。
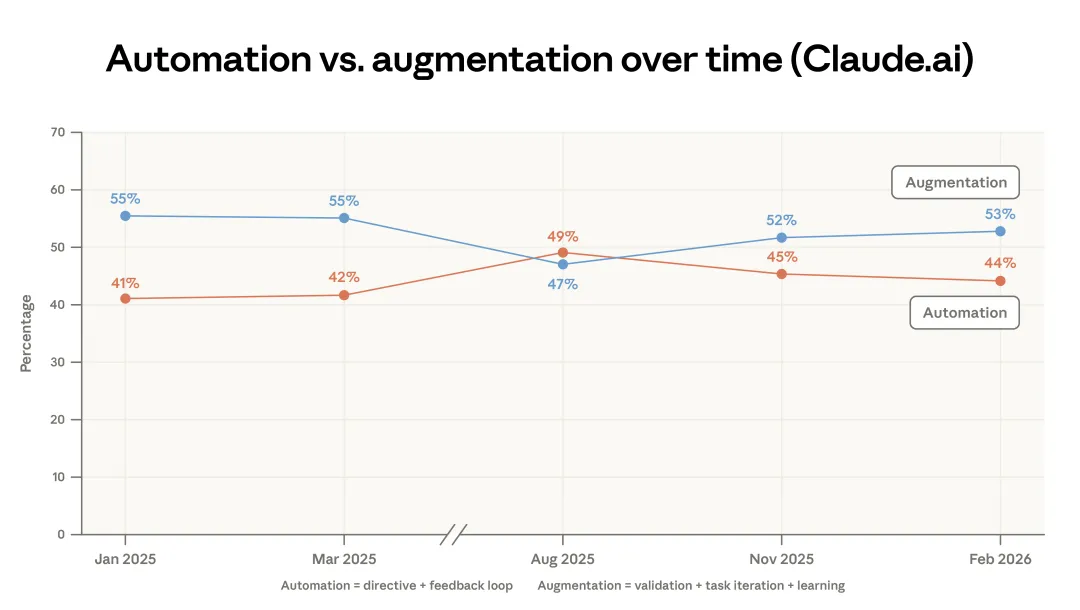
图 1.3:Claude.ai 中不同协作模式的占比变化。
我们的 API 平台继续获得更高比例的计算机和数学类任务。自 2025 年 8 月以来,这一类别的任务占比在 API 中增加了 14%,而在 Claude.ai 中下降了 18%。正如我们在那篇关于劳动力市场影响的报告里指出的,这种从 Claude.ai 向 API 的迁移,可能预示着与这些岗位相关的工作会更快发生变化。Claude.ai 中与管理类职业相关的任务占比,也从 3% 上升到了 5%。这部分增长既包括分析类任务,例如撰写投资备忘录,也包括回应客户问题。
衡量 Claude 上任务结构变化的另一种办法,是看任务平均价值的变化。这里所谓“任务价值”,指的是执行该任务的美国劳动者平均时薪(图 1.4)。(6) 对 Claude.ai 来说,这一估计值从 49.3 美元小幅降到了 47.9 美元,主要原因是体育比分、天气这类简单事实性问题增多了,而编码任务又随着迁移到 API 而占比下降。正如我们在上一篇报告里提到的,我们在 Claude 上看到的任务往往需要更高的教育程度。图中也显示,这些任务对应的工资水平,通常也高于美国全国平均水平。
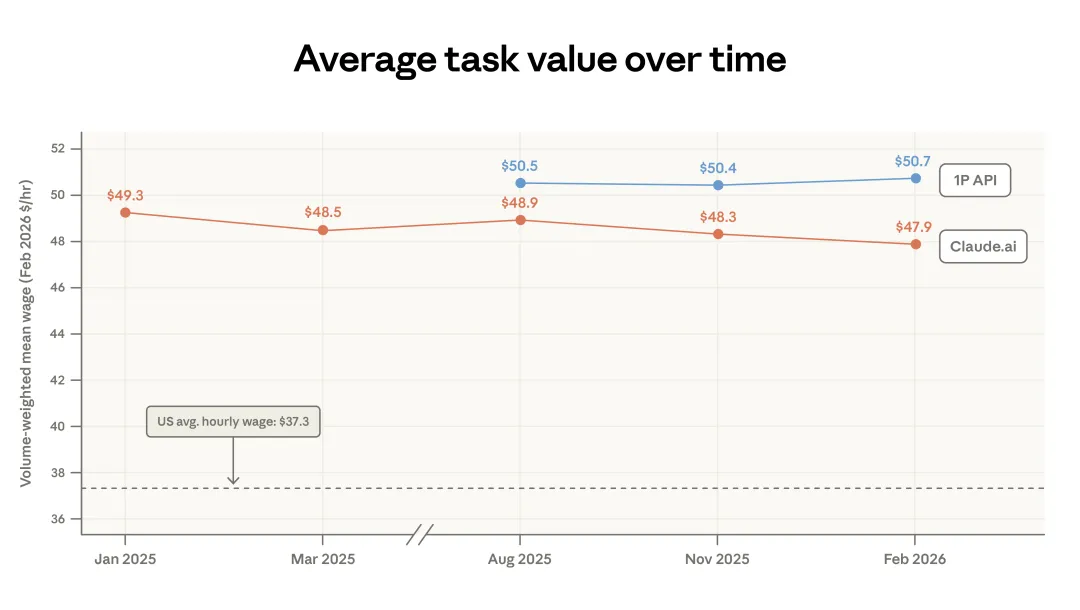
图 1.4:不同版本与平台上的平均任务价值变化。
尽管幅度不大,但本次报告与上一版在多项“经济基本单元”上的变化,都指向 Claude.ai 上任务复杂度略有下降。理解用户输入所需的平均教育年限,从 12.2 年降到了 11.9 年;用户交给 AI 的自主权更高了;如果完全由人来做,这项任务的预估时长平均缩短了约 2 分钟。唯一看起来有点反向的指标是:Claude 所做的任务,被判断为“如果没有 AI,人类是否还能完成”的概率反而略微更低。
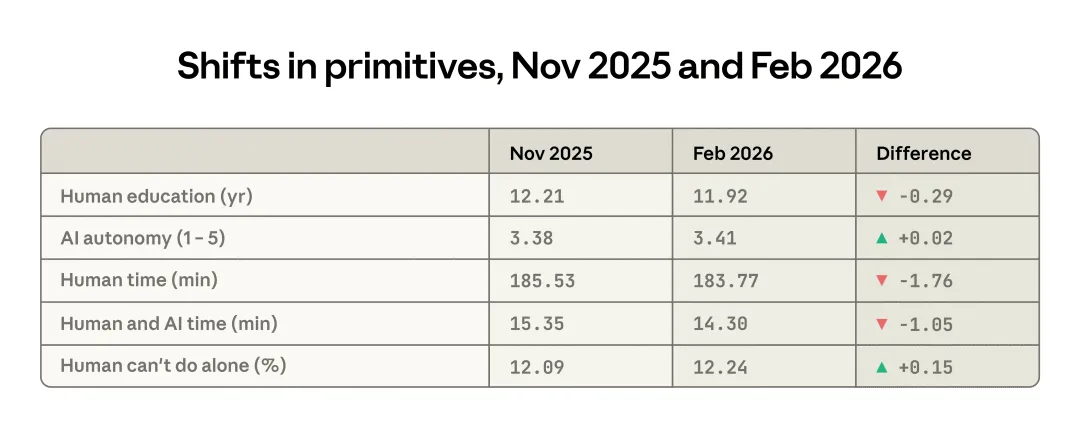
表 1.1:关键经济基本单元的变化。
新出现的自动化模式
随着任务迁移到 API,这些任务也更容易暴露在自动化之下。API 工作流更偏向指令式,对“人仍在环中”的依赖更低。上一篇报告里我们就强调过,客服任务——例如自动处理支付和账单问题——在 API 数据中非常常见。这意味着客服岗位面临更高的暴露度。换句话说,我们确实观察到,在自动化工作流里,Claude 承担了相当高比例的客服任务,因此随着 AI 继续扩散,这类岗位可能更早发生变化。
我们特别指出两类 API 工作流:与三个月前相比,它们在 2 月样本中出现得更频繁,而且在最新样本中的占比至少翻了一倍(7):
商业销售和外联自动化:销售赋能内容生成、B2B 线索资格研究、客户数据补全、冷邮件草拟。
自动化交易和市场运营:监控市场或头寸、提出具体投资建议、向交易员通报市场状况,以及相关任务。
重新看地理收敛
在上一篇报告里,我们指出,Anthropic AI Usage Index,也就是 AUI,会按地区的工作年龄人口对使用量进行调整;按这个口径看,美国各州之间的使用差距正在快速收敛:原本人均使用量更低的州,采用速度反而更快。
图 1.5 左图显示,这种收敛在最新数据里仍然存在,只是速度更慢了。从 2025 年 8 月到 2026 年 2 月,按人均计算流向前五大州的使用份额,从 30% 降到了 24%。基尼系数自 2025 年 8 月以来也有所下降,只是收敛速度放慢了。当我们更新上一篇报告中的估计时,发现按目前这个速度,美国各州的人均使用量大概会在 5 到 9 年后趋近于相等,而不再是之前估计的 2 到 5 年(8)。
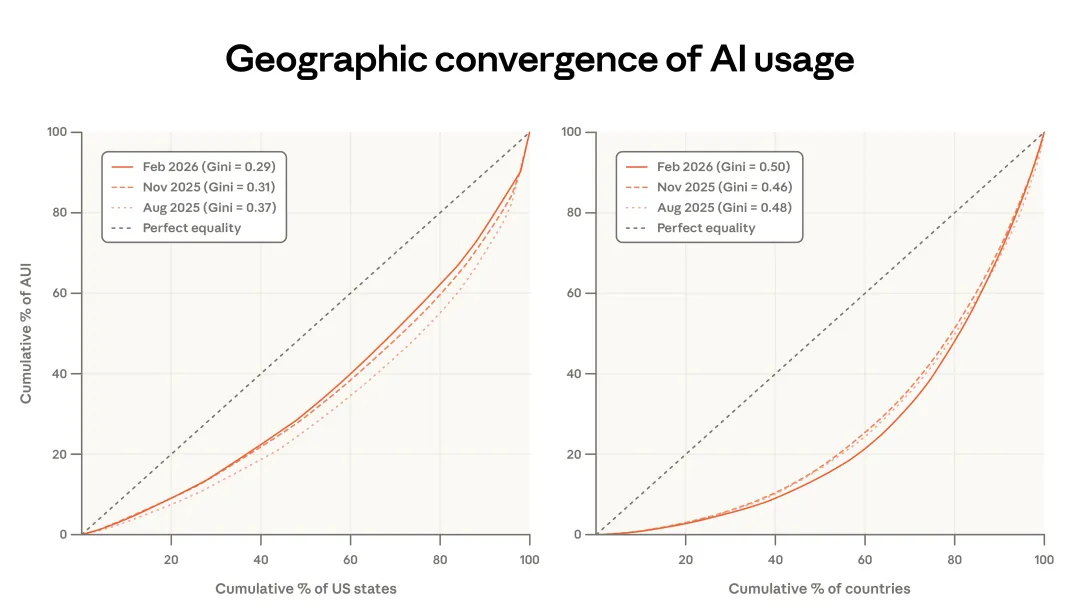
图 1.5:地理收敛。左图为美国各州,右图为各国的 AUI 洛伦兹曲线。
在国家层面,情况则相反:使用变得略微更集中了,同期基尼系数上升。按人均计算,使用 Claude 最多的国家占总体使用的份额更高了,前 20 个国家的人口调整后使用占比,从 45% 上升到了 48%。
学习如何使用 AI
这一章聚焦两个特征,它们能帮助我们理解人们是如何部署 AI、又是如何学会与 AI 协作的:一是模型选择,二是长期用户形成的使用习惯。
首先,我们通过研究人们会在什么情况下选择 Opus (也就是性能最强的模型类别) 来理解“对智能的需求”。目前,我们对用户如何在不同模型之间做选择、又如何在速度、性能和成本之间权衡,其实知之甚少。如果用户真的会根据任务难度来校准模型,那么我们就应该看到,Opus 更多地被用于更难、价值更高的工作。
接下来,我们按使用时长来研究差异,也就是根据用户是什么时候注册的,看看他们的使用方式会如何变化。这能帮助我们理解学习曲线:用户会不会随着使用时间变长而变得更擅长?他们的用法会往什么方向变化?我们的证据与“边用边学”这一解释是相一致的。使用时长更长的用户不仅在对话中成功率更高,他们也更常以协作方式使用 Claude,会把更有挑战的任务带给 Claude,也更倾向于为了工作目的、以及在更广泛的任务范围内使用 Claude。
模型选择
不同的 Claude 模型类别 (Haiku、Sonnet 和 Opus) 对应着不同的成本、速度和性能组合。Opus 类模型会消耗更多 token,在复杂任务上的表现最好,但在 API 中按 token 计价也更贵。如果用户理解这一点,同时又会权衡成本和使用上限,那么他们就会把最复杂、最有价值的任务交给 Opus,把更简单的任务交给其他模型。数据大体印证了这一点。
图 2.1 显示,在能访问全部模型类别的付费 Claude.ai 账号中,55% 的计算机和数学类任务(例如软件编码)使用的是 Opus,而教育类任务只有 45%。这可能意味着技术型用户更容易感知性能差异,所以会主动从默认的 Sonnet 切换出去;也可能意味着更注重效率的用户已经学会把简单任务交给 Sonnet,以避免触发使用上限。换个角度看,这里的差异也可能说明:大多数教育类任务对 Sonnet 来说本来就已经足够容易,或者学生用户更容易在意使用上限。
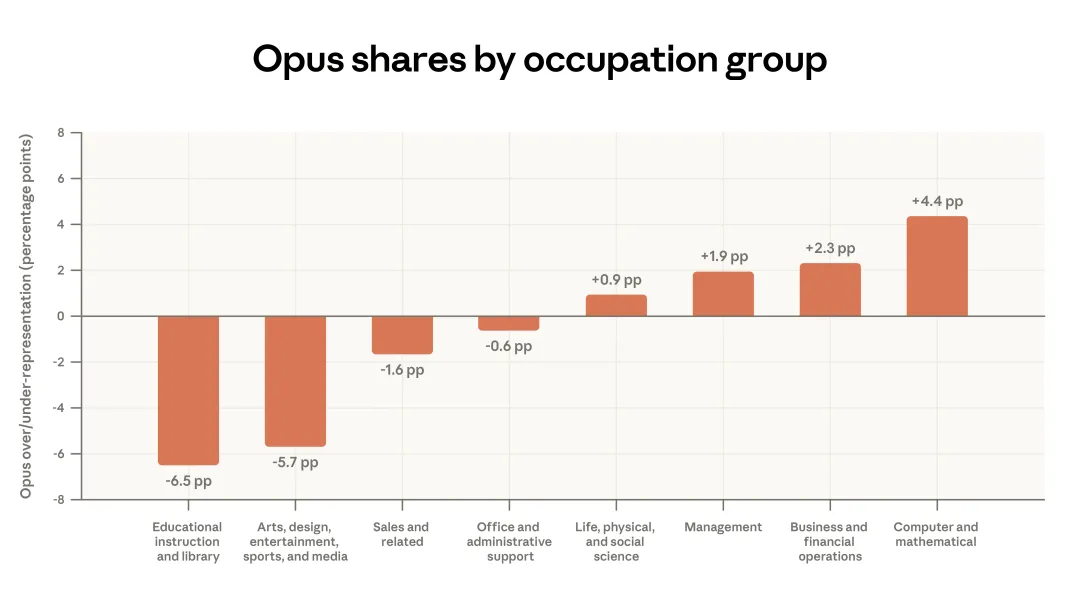
图 2.1:模型选择与职业领域。
图 2.2 则以更细粒度展示了同一现象。当用户执行与更高薪职业相关的任务时,他们会更频繁地使用 Opus。比如在 Claude.ai 上,34% 的软件开发者任务涉及 Opus,而 Tutor 任务只有 12%。整体来看,对于 Claude.ai 用户而言,任务时薪每提高 10 美元,使用 Opus 的对话占比就会上升 1.5 个百分点。第一方 API 的流量对任务复杂度的反应则更强。它的斜率大约是前者的两倍:任务价值每增加 10 美元,Opus 的占比就会上升 2.8 个百分点。相较于 Web 用户,部署程序化工作流的用户更有动力在不同模型之间切换。
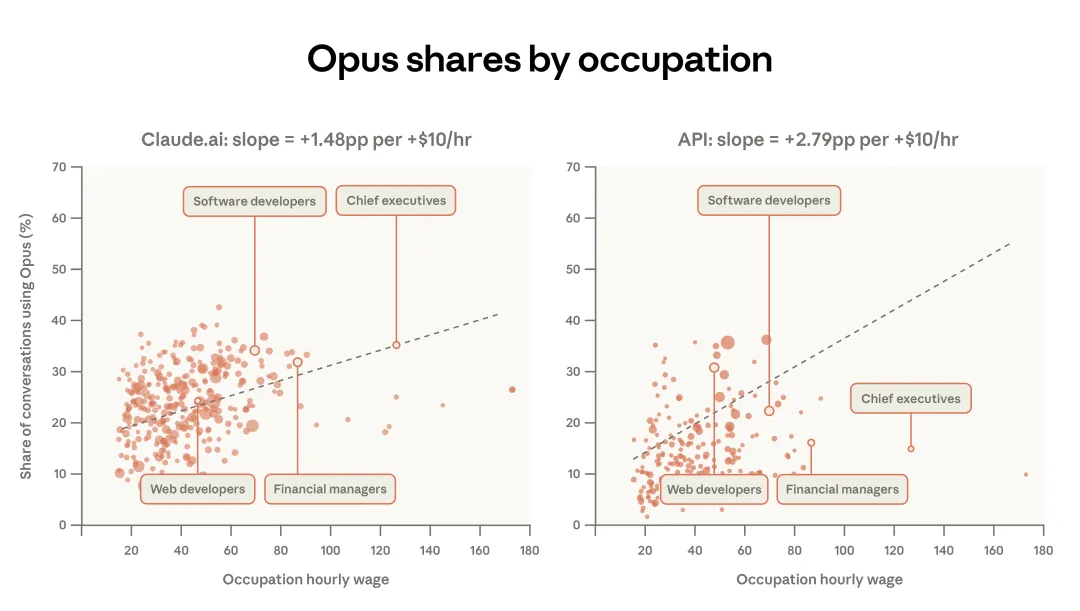
图 2.2:模型选择与职业。
学习曲线
第一个 Claude 模型发布于 2023 年 3 月。此后,无论是 Claude.ai 还是 API,用户群都迅速增长。我们的最新样本里既有在 Claude 第一版发布时就注册的老用户,也有在我们观测前一天才刚刚注册的新用户。一个人和 Claude 相处的时间长短,会如何影响他的使用体验?(9)
表 2.1 展示了使用时长较短用户与使用时长较长用户之间的差异。后者指的是在数据抽取前至少 6 个月就已经注册 Claude 的用户,前者则是其余用户。(10)使用时长较长的用户更可能把 Claude 用来反复迭代自己的工作,也更不倾向于用指令式模式把更大责任直接交给 AI。他们把 Claude 用于工作的概率高出 7 个百分点,而且交给 Claude 的任务通常也需要更高的教育水平。此外,他们的使用也没有那么集中在少数任务上。对于使用时长较长的群体来说,前 10 个 O*NET 任务占全部使用的比例略低,为 20.7%;使用时长较短的群体则是 22.2%。
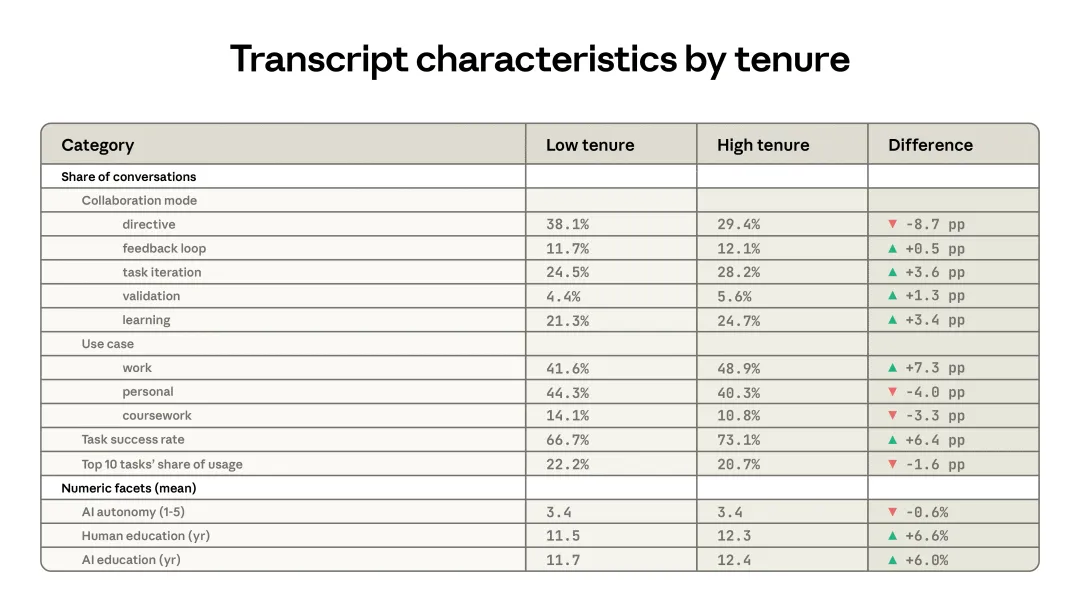
表 2.1:高使用时长用户与低使用时长用户的差异。
下面,我们进一步看前面提到的两个“经济基本单元”:每段对话对应的人类教育年限,以及对话中有多少比例属于个人用途。
左图显示,理解用户提示所需的教育年限,会随着 Claude 使用时间增加而上升。Claude 每多使用 1 年,这个年限几乎就会增加 1 年。右图则显示,个人用途占比在下降:注册满一年的用户,会把 38% 的对话用于个人用途,而新用户是 44%。
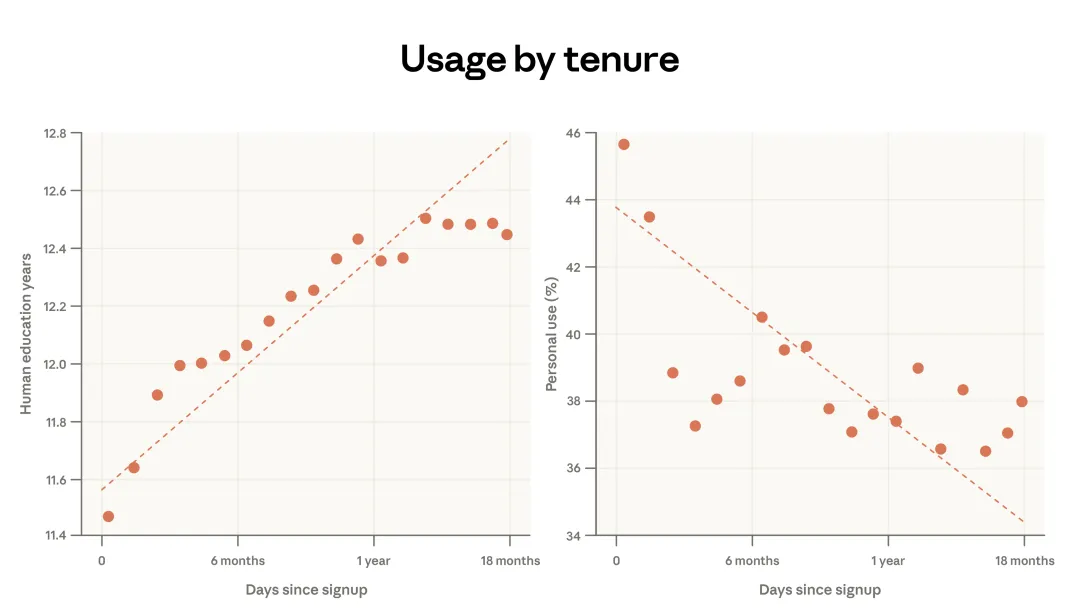
图 2.3:使用时长与教育年限、个人用途的相关性。
对于这种快速演进的通用技术,用户群体中出现这些模式,可能有多种原因。使用时长较长的用户,本身就是“留下来的人”,这种差异也可能反映一些更稳定的特征。比如,他们可能本来就是程序员,而程序员本来就更容易成为早期采用者。再进一步说,这里还天然存在幸存者偏差:那些在数据抽取前一年就注册、并且今天仍在使用 Claude 的人,可能原本就已经从中获得了积极结果。
我们并不能观测那些一年前注册了 Claude、但后来已经不用的人。
这些发现,与我们在《Economic Primitives report》中看到的现象是一致的:在一些收入更低、教育水平更低的国家,反而会在某些场景中出现更复杂的使用。最早的一批采用者,往往拥有高价值、技术含量更高的用例。在采用率远低得多的较贫穷国家里,这些早期采用者仍然主导着用户群。
更休闲的使用,则通常要等 AI 扩散到更广泛人群之后才会出现。确实,在各个请求簇中,平均使用时长最高的任务包括 AI 研究、git 操作、修改手稿和创业融资;而平均使用时长最低的任务,则更多是写俳句、查体育比分和为派对推荐食物这类简单工作流。(11)
经验效应
我们在图 2.4 中进一步考察这些关系,使用日志级别的数据,对对话特征做了更细的控制。上方图中的规格 (1) 是一个简单的双变量回归:把任务是否成功作为结果变量,把“是否属于使用时长较长用户”作为预测变量。这里的“成功”,指的是 Claude 对这段对话是否成功的判断,这个定义在上一篇报告中已经解释过。
图中显示,长期用户成功完成一段对话的概率大约高出 5 个百分点。
这可能意味着,使用时长较长的用户更擅长写提示词。但如果这只是因为他们交给 Claude 的任务不同,而那些任务本来就更容易成功呢?
在规格 (2) 中,我们加入了针对具体 O*NET 任务和请求簇的固定效应。也就是说,我们比较的是同一个狭义任务内部,使用时长较长用户和使用时长较短用户之间的差异,而不是拿不同任务之间做比较。举例来说,我们有一个请求簇叫作“对特定公司进行企业财务分析、估值和建模”。固定效应的含义,就是在这个请求簇内部比较这两类用户,在每个其他请求簇内部也同样如此。只有当长期用户在这些“同任务比较”中平均更成功时,我们才会观察到正系数。这个控制让效应有所减弱,降到了接近 3 个百分点。
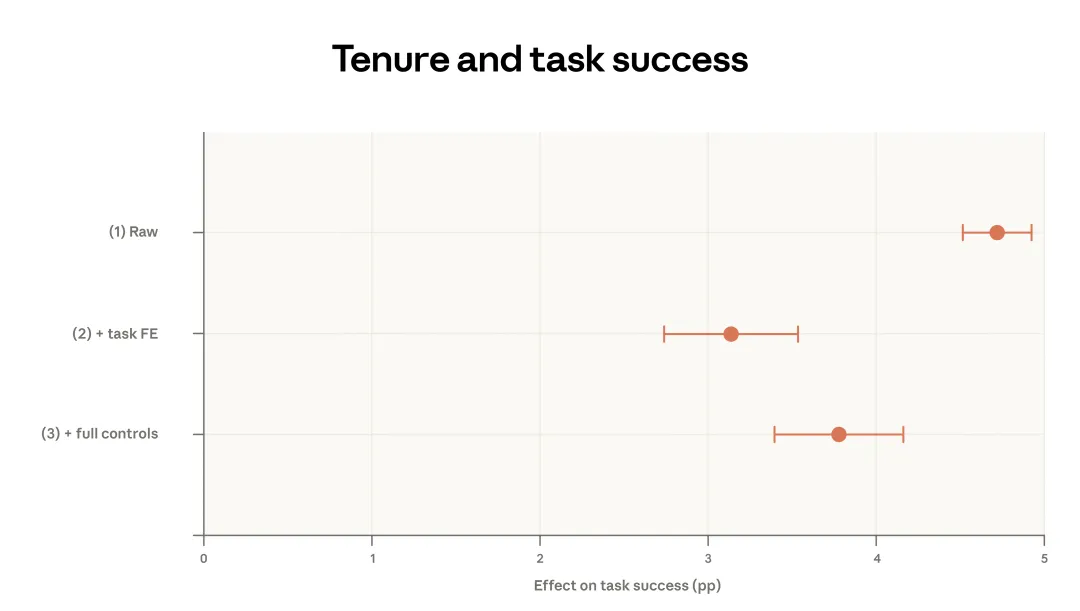
图 2.4:经验与成功率之间的关联。
最后,我们进一步问:这种关系会不会其实是由其他因素造成的,比如使用时长较长的用户更倾向于选择不同模型、使用不同语言、拥有不同用例,或者身处不同国家?在把这些因素控制进去之后,回归结果反而给出了略高的影响,表明在完全控制后,使用时长较长用户的成功率仍然高出约 4 个百分点。
这些结果表明,使用时长较长的用户在与 Claude 的对话中更容易成功,而且这并不是由语言、任务类型这类简单因素造成的。一个很有意思的解释是,这些用户更会从 AI 身上提取自己真正想要的结果。使用这些平台的熟练度,可能本身就是一个关键的成功因素,而且它似乎会随着经验增长而提升。
讨论
这份报告重新检视了我们用来追踪 Claude 使用情况的核心指标,并首次分析了模型选择与成功率。自 2025 年 8 月以来,第一方 API 的使用变得更集中,前 10 个 O*NET 任务现在占了全部流量的 33%,高于此前的 28%。另一方面,Claude.ai 上的任务则比 2025 年 11 月那次数据更为多样。美国内部,低使用州的采用速度仍然更快,只是收敛速度比上一篇报告时慢了一些。而低采用国家则又稍微落后了一些。
借助这份报告,我们开始能够持续追踪各种经济基本单元是如何变化的。课程作业类用途在全部使用中的占比下降了,而个人对话则增加了。我们也观察到,Claude.ai 上提示词的总体复杂度略有下降:输入变得没那么复杂,预估完成时间也更短。
总体来看,Claude 仍然主要被用于高价值、复杂的工作,因此它并不能广泛代表美国经济的整体面貌。但随着用户群扩大,报酬较低的任务在 Claude.ai 中的占比的确略有上升。按任务所对应职业的工资来估算,Claude.ai 上的平均任务价值自第一份报告以来有所下降,而 API 用户那边则有所上升。在这两个场景中,用户都会把自己最复杂的任务交给更强的模型类别 Opus。对于 API 客户来说,这种分化表现得更明显。
更有经验的用户,往往会以更协作的方式使用 Claude,把它用于更多与工作相关、也更复杂的任务,而且成功率也更高。这反过来挑战了我们去年提出的一个假设:自动化用法可能更典型地属于更有经验、更成熟的用户。相反,我们发现,最先进的一批用户更可能与 Claude 反复迭代。这也与“边用边学”一致:一个人使用 AI 的时间越长,就越擅长调动它的能力。
当然,也还有另一种解释:这些结果可能是由同期群体效应或幸存者偏差驱动的。早期采用者本来就可能更技术化;持续使用 Claude 的人,也可能本来就拥有更适合 Claude 发挥的任务。但经过严格控制后的回归分析,已经排除了这种混杂因素最简单的版本,比如“长期用户只是带来了不同类型的任务”。随着时间推移,我们会更清楚地把同期群体效应、幸存者偏差和“边用边学”区分开来。
这些被观察到的成功率差异,可能会加深劳动力市场中的不平等。经济学家早就注意到,技术变革往往会偏向技能更高的人:创新会提高高技能劳动者的工资,同时压低其他人的处境。我们的分析识别出了一条这种变化可能已经在发生的路径:那些执行高技能任务的早期采用者,在与 Claude 的互动中,比后来进入、技术性更低的采用者更容易获得成功。这些早期采用者,可能既是最容易受到 AI 扰动的一群人,也是在最初这波增强型采用浪潮中最先从 AI 身上获得帮助的一群人。
附录
附录见原文附录页面。附录链接:https://cdn.sanity.io/files/4zrzovbb/website/a3cdcd9e67c3c4c51440429dd016cacba514b35b.pdf
数据可得性
本报告的数据可在原文中的 Data availability 部分获取。
数据链接:https://huggingface.co/datasets/Anthropic/EconomicIndex
作者与致谢
第一作者组:Maxim Massenkoff、Eva Lyubich、Peter McCrory。
第二作者组:Ruth Appel、Ryan Heller。
致谢:Tim Belonax、Keir Bradwell、Andy Braden、Dexter Callender III、Miriam Chaum、Madison Clark、Evan Frondorf、Deep Ganguli、Kunal Handa、Hanah Ho、Owen Kaye-Kauderer、Jennifer Martinez、Miles McCain、Jared Mueller、Kelsey Nanan、Tyler Neylon、Dianne Penn、Sarah Pollack、Ankur Rathi、David Saunders、Michael Stern、Alex Tamkin、Kim Withee、Jack Clark。
引用格式见原文 Citation 部分。
脚注
“第一方 API”或 1P API,指的是直接通过 Anthropic 自有编程接口进入的开发者流量,这不同于 Anthropic 面向消费者的 Claude.ai 应用,也不同于 Amazon Bedrock 或 Google Cloud Vertex 这类第三方平台。 这里也包含了 Claude Code 的数据。 这里使用的是 2019 年版 O*NET-SOC 编码,而前几份报告使用的是 2010 年版。 在我们抽样期间,仍在学期内的国家里,课程作业对话下降了 5 个百分点;而在大多数学生处于假期的国家里,这个降幅达到 12 个百分点。 各类互动类型的定义见附录。 例如,任务“使用数学和化学方法计算水分、含盐量、配方比例或其他产品因素”,只由食品科学技术员执行,而该职业平均时薪为 26.15 美元,因此这项任务的价值就按这个数值估算。所用数据来自 2024 年 5 月美国劳工统计局职业就业与工资统计(OEWS)表。当同一任务由多个职业承担时,我们会按就业人数和该任务所占工作时间加权平均他们的工资。 为了识别这些新出现的模式,我们筛选了两类 O*NET 任务:一是当前样本中至少出现 300 次,二是与上一篇报告相比增长至少达到 2 倍。 这里给出一个区间,是为了反映在上一篇报告模型中使用加权(得到 5 年)与不加权(得到 9 年)时的不同估计。 在这一分析中,我们使用日志级数据,并在相同的隐私阈值下估计模型。更多方法细节见附录。 无论如何定义“高使用时长”,结论都大体一致。 我们的抽样期恰好与 Super Bowl 广告投放重合,这带来了很多首次使用的新用户。

