
📄 本文PDF完整版已上传云盘,点击链接保存后可随时查阅:https://pan.quark.cn/s/752c18076a95
先把结论放前面:
先进封装正在从“把芯片装起来”,变成“把性能做出来”。
当传统制程微缩越来越慢、越来越贵,AI 算力需求却在加速,性能的下一跳,很大一部分要靠 2.5D/3D 堆叠把互连带宽和系统效率顶上去。
从材料看,这个趋势不是短炒。
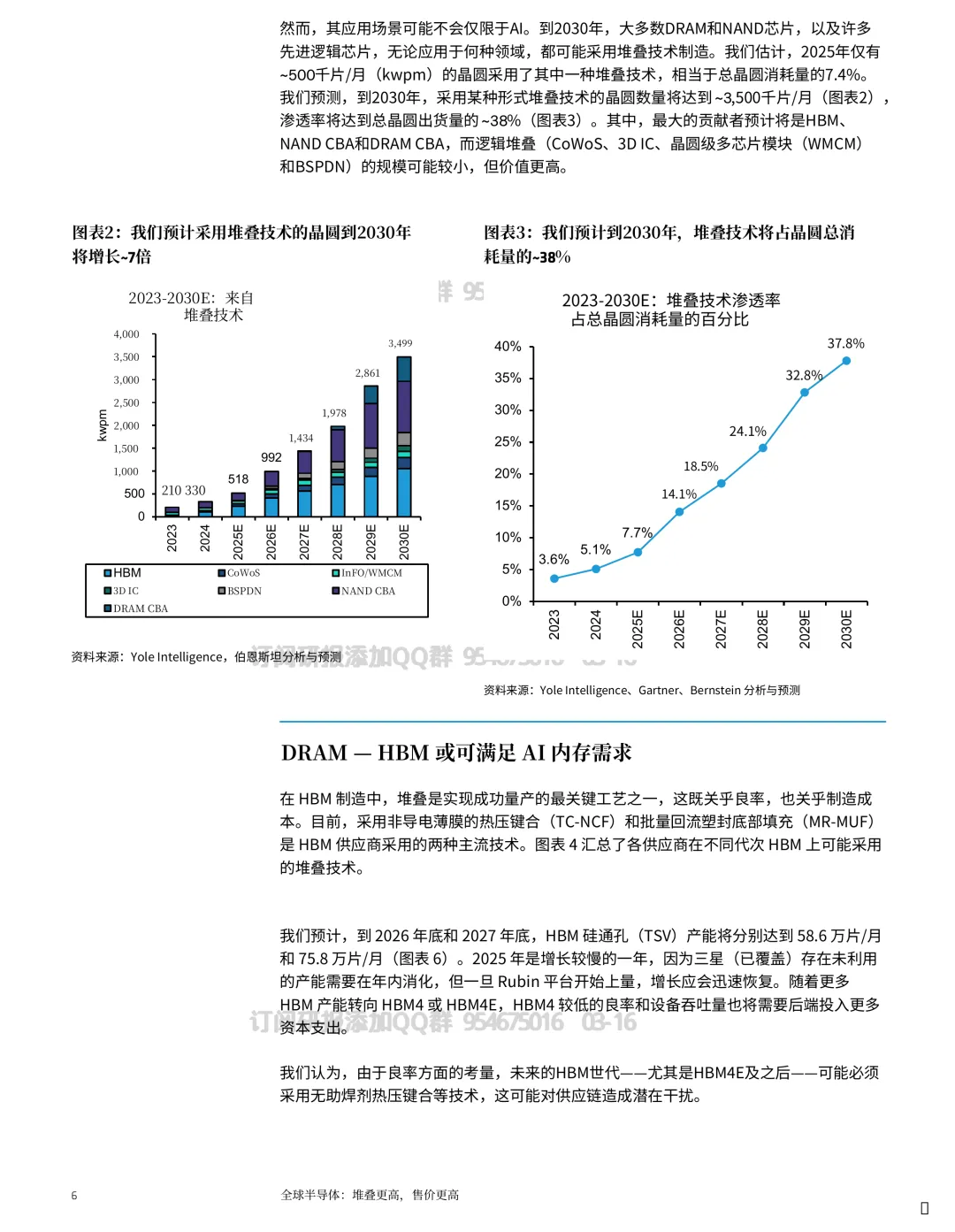
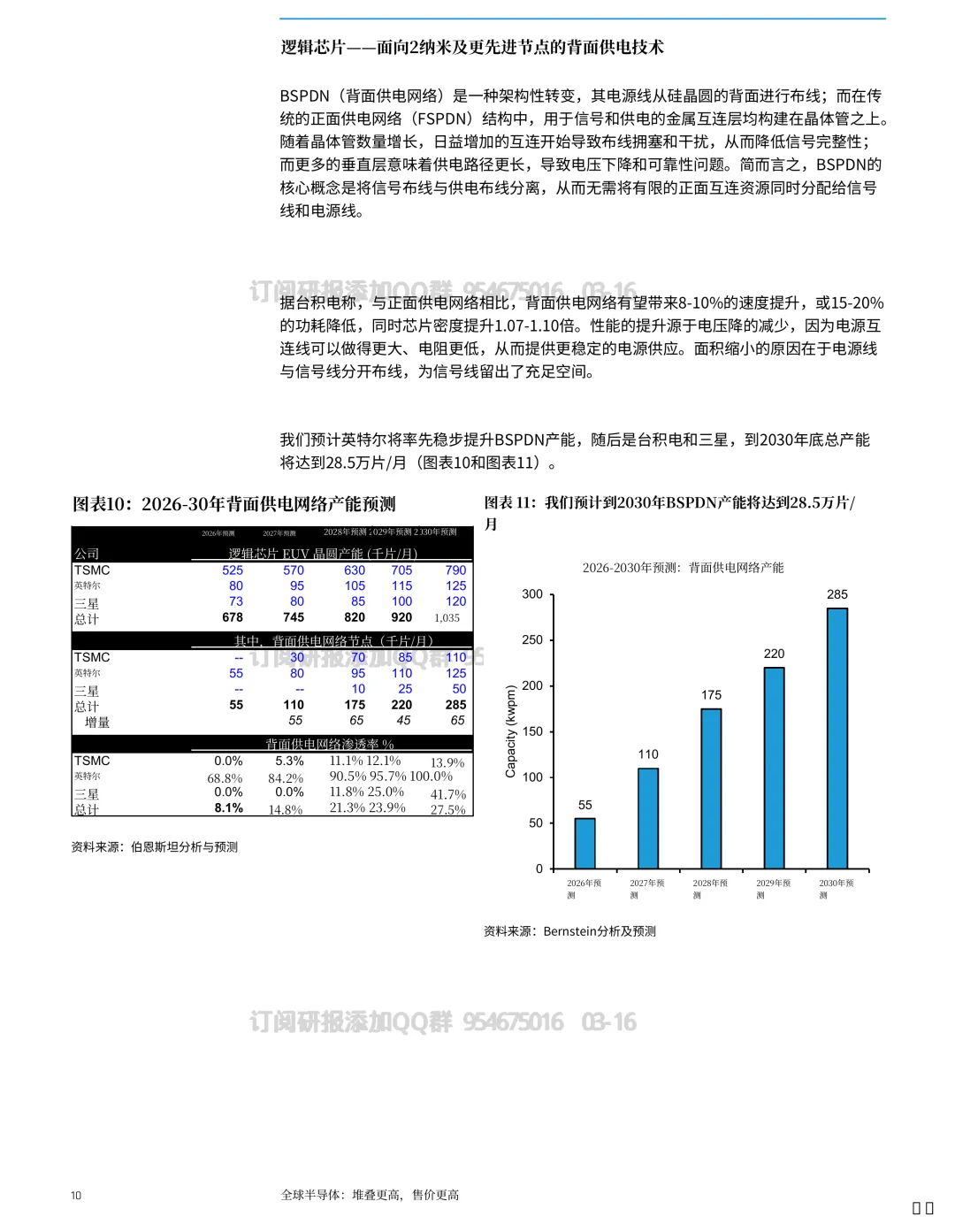
到 2030 年,与堆叠相关的晶圆消耗量可能出现约 7 倍增长,渗透率可能到 ~37%。
换句话说:未来很多芯片(不只 AI)可能都会“长在封装里”。
为什么“封装”突然变成主角
传统逻辑:更先进制程 = 更高性能。
现在的问题是,微缩进入后摩尔定律时代后,成本上升、物理极限、收益递减一起出现。
同时,系统级瓶颈更突出:互连带宽、内存墙、功耗与散热。
先进封装的价值在于:
把多个裸片当作“一个芯片”来通信和协同工作。
核心不是外形,而是更短的连线、更密的 I/O、更高的带宽、更可控的热与能效。
2.5D/3D 堆叠:AI 性能指数级提升的“工程解法”
材料里把堆叠拆成两类:
- 2.5D:多个裸片放在中介层上(典型例子是 CoWoS),解决高带宽互连与系统集成。
- 3D:裸片彼此堆叠(例如 SoIC、混合键合),走向更小间距、更高 I/O 密度。
它们并不互斥,反而在融合。
例如材料提到的路径:AI GPU/ASIC 的封装会把 3D 堆叠与 2.5D 封装结合,形成更高密度的系统级集成。
从材料判断,未来几年随着对芯片间密度需求继续提升,3D 混合封装的增速可能会超过 2.5D。
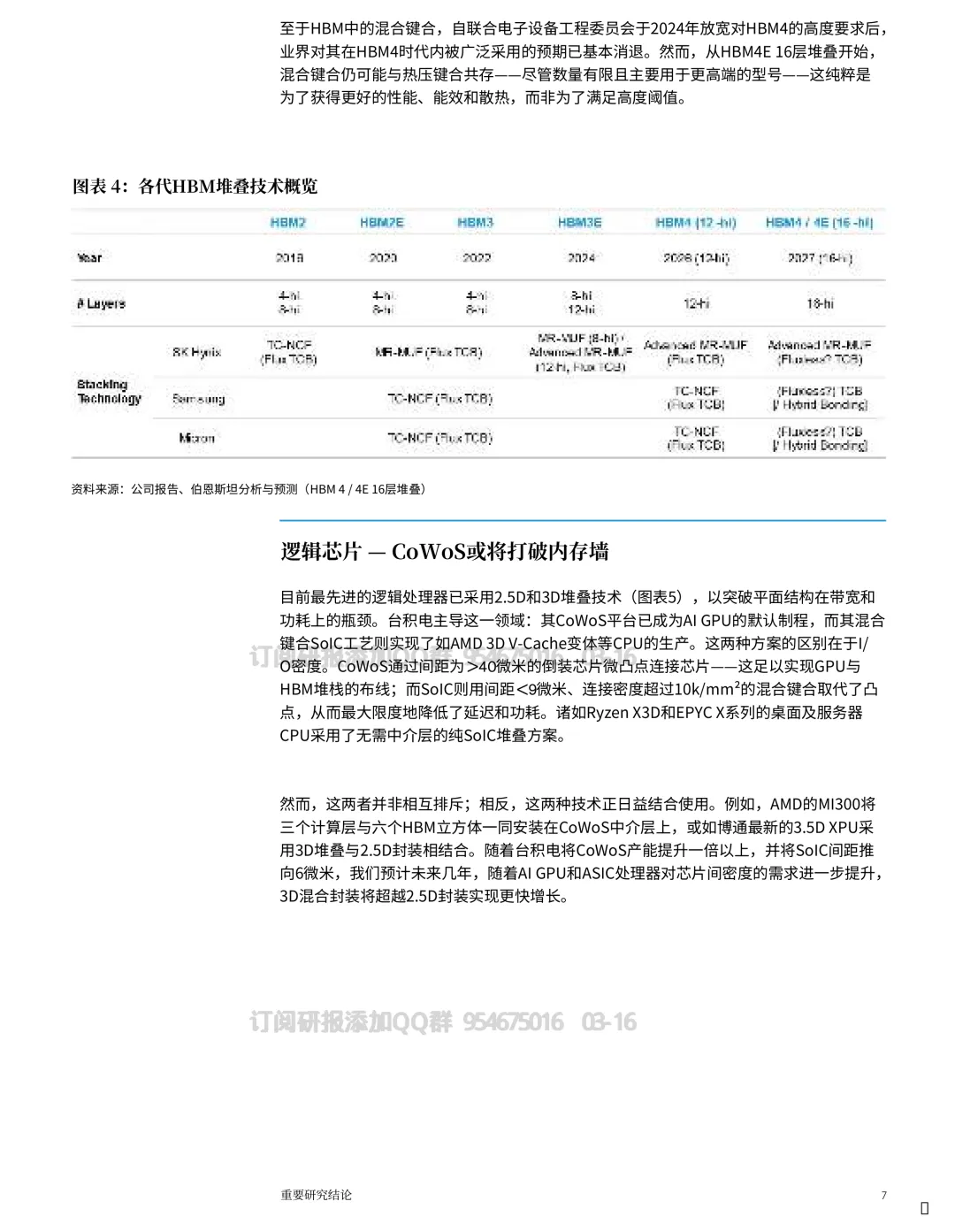
HBM:内存不够快,就把内存“堆高”
AI 算力的痛点不只是算,也在喂数。
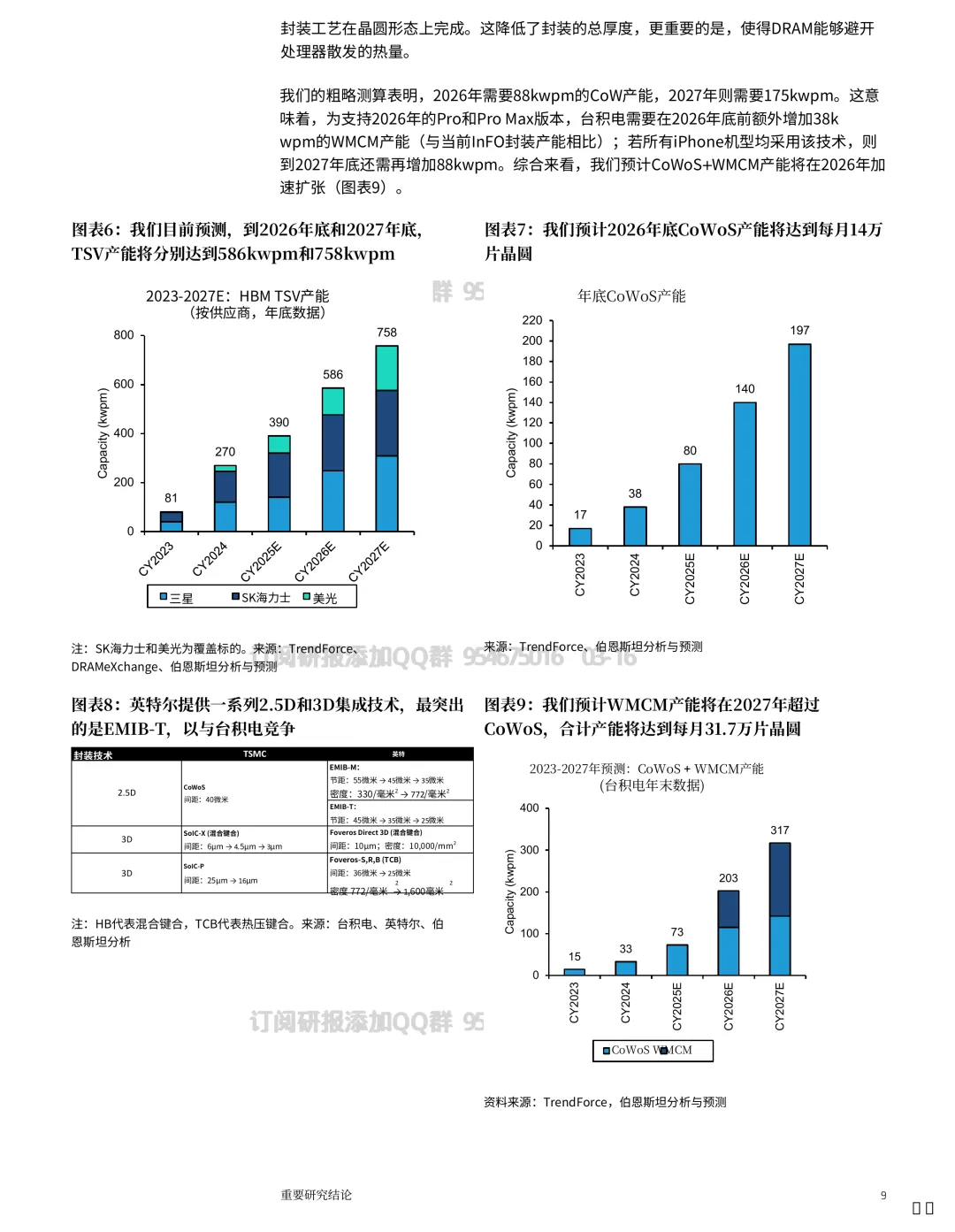
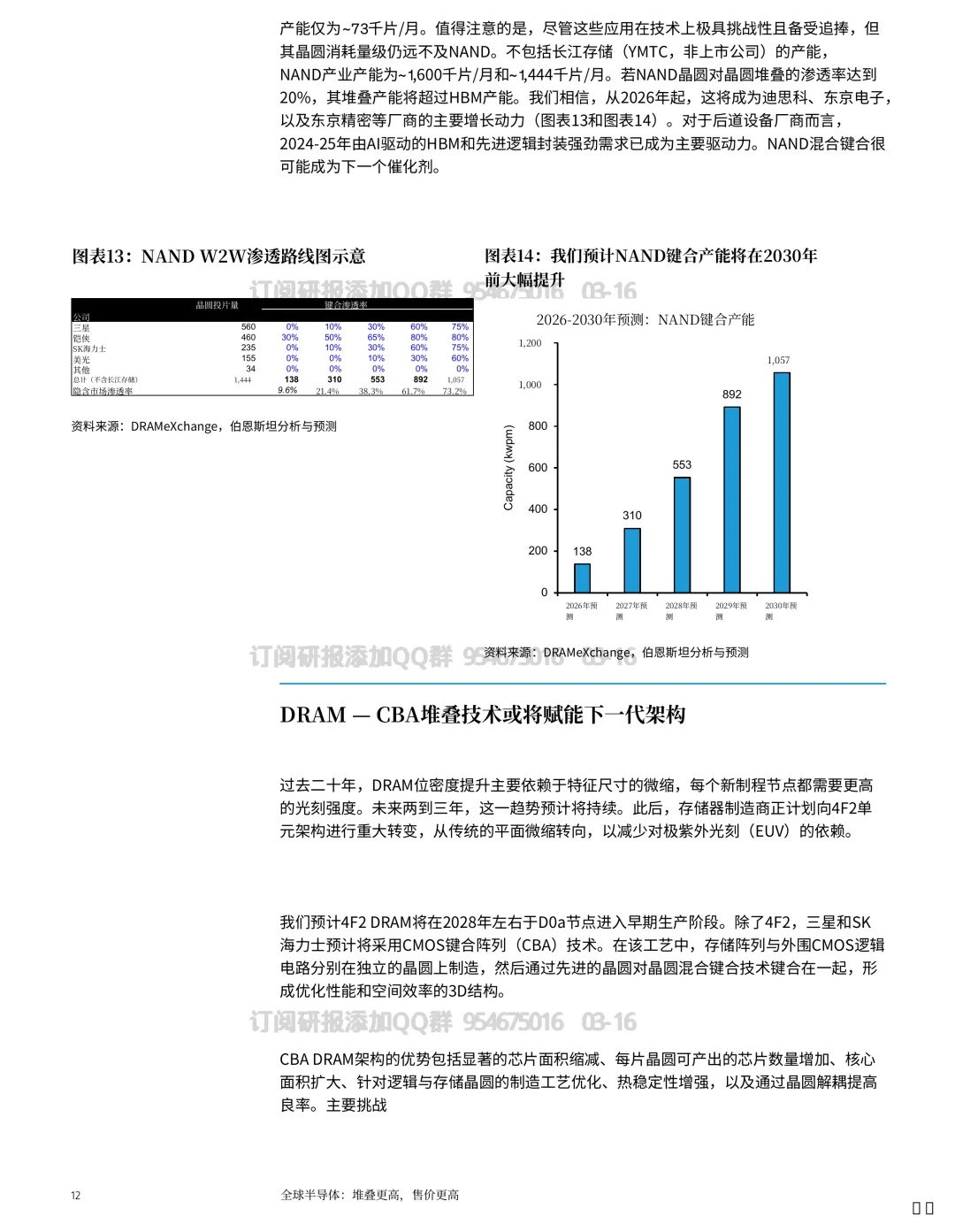
材料里给出一个很清晰的判断:HBM 产能会随着 AI 加速器出货与堆叠层数上升而快速扩张,到 2027 年可能到 ~758kwpm。
工艺演进也很关键:
行业正从基于助焊剂的 TCB 工艺,走向无助焊剂,再走向混合键合,以实现低于 10μm 的节距。
这背后的含义是:
- 带宽上去
- 热管理更好
- 能效更优
而这些,都是 AI 集群“每瓦性能”的命门。
CoWoS:打内存墙,但产能仍紧
材料对 CoWoS 的描述很直接:它是 AI GPU/ASIC 扩产的关键承载方式。
产能预计到 2027 年可能到 ~140kwpm,但仍可能保持紧张。
为什么会紧?
从材料看,一方面是芯片尺寸更大、GPU/ASIC 更复杂,封装难度上升;
另一方面,行业可能向“晶圆级系统”的方法迁移——用一整片晶圆支撑一个更大的器件形态——这会进一步抬高晶圆需求。
这里的投资/产业逻辑更像“基础设施扩容”:
需求一上来,不是你想多造就能多造,限制往往在设备、良率、工艺窗口、材料与产线爬坡速度。
混合键合 3D IC:把 I/O 密度与能效再推一档
材料强调混合键合(铜对铜直接键合)的优势:
I/O 密度、能效、热性能都有显著提升。
并且已经出现商业化与跟进:
材料提到 AMD 已实现混合键合 3D IC 的商业化,英特尔与博通也在向同一方向推进。
如果把它类比成“下一代互连范式”,那它的意义在于:
不是再去赌某个单点制程的神迹,而是用系统工程把性能挤出来。
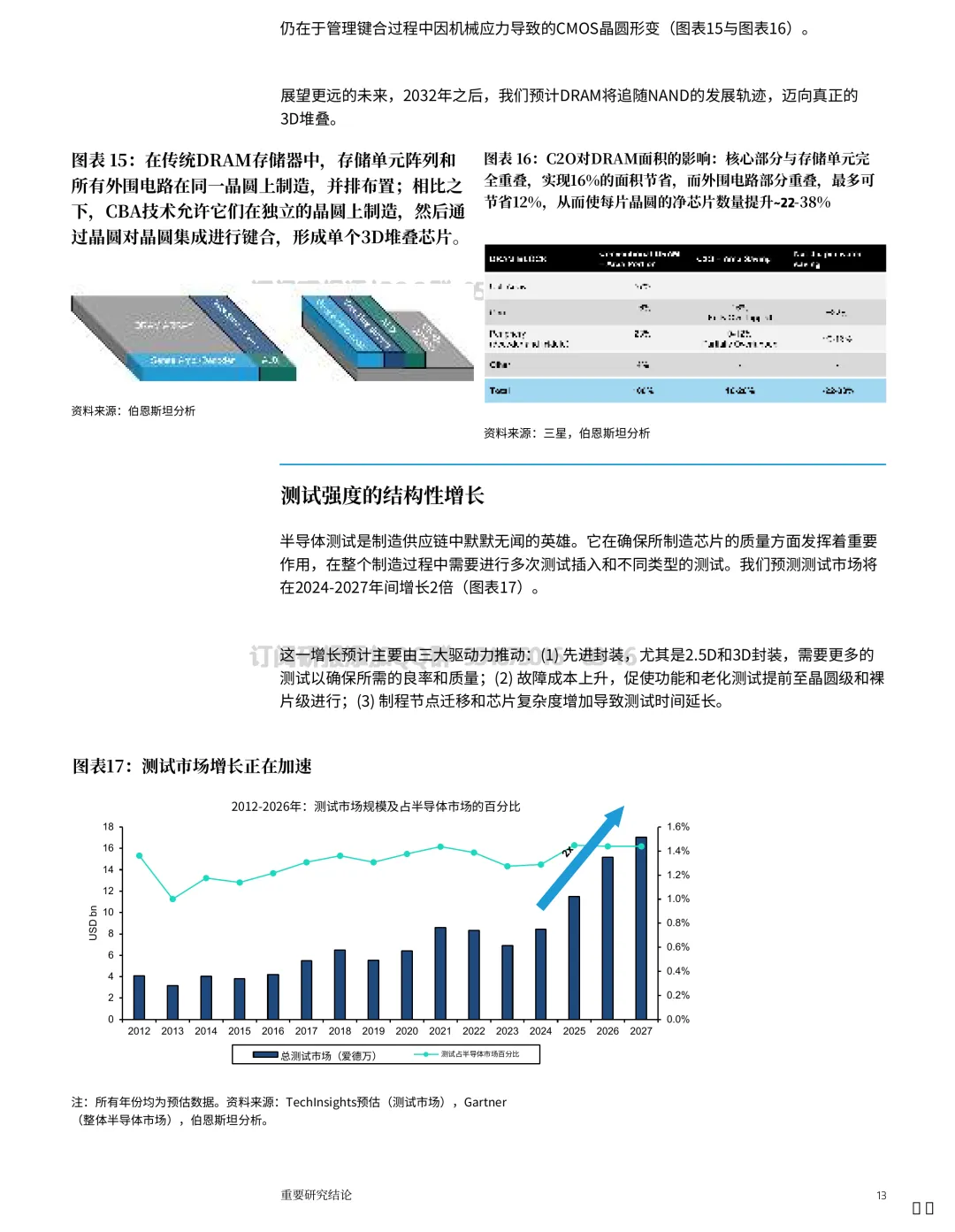
存储的 CBA:把存储单元和外围电路拆开做
材料提到 NAND/DRAM 的 CMOS 键合至阵列(CBA)路线:
把存储单元与外围 CMOS 电路分离到各自优化的晶圆上,提高 I/O 性能,并允许更灵活的工艺条件。
并且材料给了落地信号:
NAND 侧已经开始采用(提到铠侠与长江存储),DRAM 预计会跟上,甚至可能出现多层晶圆键合方案。
这条线的共同点仍然是:
用“拆分 + 堆叠 + 键合”去换性能、换效率、换可扩展性。
这份报告对我们有什么用:可执行检查清单
1) 看增长变量:关注 2.5D/3D 渗透率与晶圆消耗量的爬坡节奏(材料给到 2030 年 ~7× 的方向性)。
2) 看产能与瓶颈:HBM、CoWoS 这类关键环节的产能扩张是否跟得上,以及“仍紧张”的持续性。
3) 看工艺拐点:TCB → 无助焊剂 → 混合键合的迁移是否如材料所述推进到 <10μm 节距。
4) 看组合形态:2.5D 与 3D 的融合会不会成为主流(尤其是 AI GPU/ASIC 的封装形态)。
5) 看受益方向:设备、材料、制造产能是最直接的受益链条;但落地节奏最终由良率、工艺窗口和客户导入速度决定。
以下为原文预览:








需要查看更多专题研究报告,可以微信扫一扫/长按识别下方优惠券付费成为会员,30000+份报告,随意下载,不受限制,报告涵盖全行业。
【大吉行业专题报告库】:公众号@大吉研报星球
作者 选择加入即可获得:
1. 星球精选专题研报
2. 1v1研报专题定制整理、查找与下载服务

戳“阅读原文”下载报告

