
你的电脑里,是不是也有这样一个文件夹?
名字叫"行业资料",里面塞满了:
《2026年AI硬件趋势分析.pdf》 《SaaS产品定价策略白皮书.docx》 《竞品功能对比表.xlsx》 《某大佬分享会笔记.md》 总大小:47.8GB。使用频率:0次。
每次写策划案、做产品规划时,这些知识就像沉在海底的宝藏——你知道它们存在,但就是捞不上来。
今天,我教你用 OpenClaw 搭建一个自我生长的业务知识库。不需要你懂复杂的编程,只需 30 分钟,让碎片知识自动编织成你的"行业认知体系图谱"。

一、知识管理的三大死亡陷阱
陷阱1:收藏即学会
“先马后看” → 永远不看。 微信/Cubox 收藏1000+文章 → 打开率不足1%。 以为存下来就是自己的 → 实际只是占硬盘的数字垃圾。
陷阱2:碎片不成体系
今天看 Agent,明天看 SaaS,后天看跨境电商。 每个领域都懂一点,每个领域都不精通。 知识像散落的珍珠,缺少一根能串起来的线。
陷阱3:用时找不到
明明记得看过某篇报告。 死活想不起精准关键词。 翻遍所有文件夹,耗时2小时 → 放弃。
最终的结果就是:
写策划案时,大脑一片空白。 做竞品分析时,只能现查现搜。 和行业大佬聊天时,接不上深层次的话。 - 你的知识资产,正在以每天1%的速度贬值。
二、OpenClaw知识管家:从"收藏夹"到"认知图谱"
在这个AI一秒钟能生成十万字的时代,知识的“占有量”已经不再是护城河,知识的“连接度”才是。
传统知识管理 vs OpenClaw知识管家:
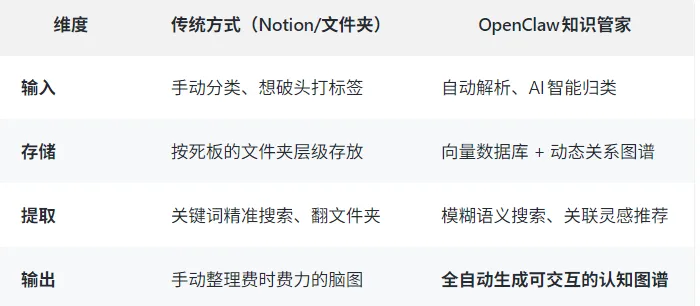
它的核心黑科技:
- 全格式解析器
把 PDF、Word、Excel 甚至长图自动拆解,提取核心结论、数据和概念。 - 隐藏关系提取引擎
自动发现文档 A(比如底层技术)和文档 B(比如商业模式)之间的隐性关联。
三、30分钟实操:搭建你的"自动驾驶"知识库
注:以下教程专为产品经理、运营等非研发职场人设计。只需要懂一点基础的复制粘贴,不需要写复杂的逻辑代码。
第0步:获取"数字大脑"的钥匙(2分钟)
打开浏览器,访问自己喜欢的大模型官网如千问等,免费注册一个账号,在个人后台生成一串属于你的 API Key(这就像是你知识库的专属通行证,请复制保存好)。
第一步:极简安装环境(3分钟)
打开你电脑的终端(Mac 用户打开 Terminal,Windows 用户打开 CMD 或 PowerShell),输入以下两行命令,安装 OpenClaw 的一键包,并建一个知识库文件夹:
bash 复制编辑 & 运行
# 1. 安装 OpenClaw 命令行工具 (确保电脑有安装基础的 Python 环境)pip install openclaw-cli# 2. 在桌面创建一个你的专属知识库目录mkdir -p ~/Desktop/MyKnowledgeBase/rawcd ~/Desktop/MyKnowledgeBase
第二步:配置你的"知识捕鼠夹"(5分钟)
在 MyKnowledgeBase 文件夹下,新建一个文本文件,命名为 config.yaml。用记事本打开它,把下面的配置粘贴进去:
yaml 复制编辑 & 运行
# OpenClaw 知识库极简配置auth:api_key:"sk-在这里填入你刚才第0步获取的 API_KEY"settings:workspace:"./"# 当前工作目录target_dir:"./raw"# 你平时扔各种PDF、文档进去的文件夹extraction_rules:-extract_concepts:true# 自动提取行业概念-extract_data:true# 自动抓取报告里的核心数据-build_relations:true# 自动寻找文档间的关联性automation:auto_scan:trueschedule:"weekly"# 每周自动扫一遍新扔进去的文件
配置完成!以后你只需要把平时看到的杂乱 PDF、研报、笔记无脑往 raw 这个文件夹里扔就行了。
第三步:一键扫描,见证奇迹(5分钟)
回到终端,敲下启动命令:
bash 复制编辑 & 运行
openclaw start --config ./config.yaml
屏幕上会立刻跳出进度条:
📄 正在解析: 《2026年AI行业趋势分析.pdf》… 提取了 12 个核心概念📄 正在解析: 《竞品定价表.xlsx》… 发现关联观点!🕸️ 正在使用 AI 构建关系网…
四、知识开始产生"复利":点亮你的认知星空
当终端提示“处理完成”后,输入最后一行命令启动可视化面板:
bash 复制编辑 & 运行
openclaw ui
此时,打开浏览器访问 http://localhost:3000。深呼吸,准备迎接属于你的高光时刻。
你会看到深色的背景上,你存放在硬盘深处那几十个 G 死气沉沉的文档,此刻已经变成了数百颗发光的星辰。它们通过 AI 自动发现的知识脉络被相互连接,正在动态地呼吸、旋转。
这不仅是酷炫,更是你极其强大的外脑:
- 宏观鸟瞰视图
你会清晰地看到知识聚类。“AIGC"节点自动向外延展连接了"大语言模型”、"提示词工程"和"商业化落地"三个次级圈层。 - 微观溯源视图
点击任意一个发光的"观点"节点(例如:2026年SaaS大概率转向按Token计费),侧边栏会立刻显示出这个结论来源于哪 3 份你半年内存入的券商报告,并高亮原出处。 - 知识盲区探测器
OpenClaw 会用红色虚线标识出图谱中的"知识断层",提醒你:“你的竞品资料库很丰满,但缺乏定价策略的理论支撑,建议补充阅读相关材料。”
五、日常应用场景:如何用图谱“开挂”工作?
场景一:写竞对分析报告(效率提升 300%)
以前:打开十几个 PDF 来回切屏,找竞对的数据,头晕眼花。现在:直接在图谱搜索框向你的 AI 提问:"对比 A公司 和 B公司 在去年的定价策略差异"。OpenClaw 会沿着星空图谱的网状关系,自动从2个月前的研报、上周截取的竞品官网长图、以及你昨天看播客写的零碎笔记中,瞬时抓取所有相关数据,直接为你吐出一份结构清晰的对比表格。
场景二:化解老板的突然提问
老板突然发难:“最近头部大厂都在提『Agentic Workflow』,咱们业务能怎么结合?”你再也不用去百度搜那些疯狂同质化的水文。唤醒 OpenClaw 助手,它会基于你往期精读过、认可过的高质量资料,生成一段极其精准、契合你们行业特性的深度回答。
结语:做知识的建筑师,而不是搬运工
那 47.8GB 躺在硬盘里的资料不是垃圾,它们只是在等待被唤醒的原材料。
通过 OpenClaw 把碎片化的文档交给 AI 去解析、去关联、去生长,你就能从一个疲劳的"知识搬运工",蜕变成一个站在认知高地的"知识建筑师"。
今晚行动指南:抽出 30 分钟,拿你电脑里最乱的那个"杂项资料"文件夹开刀,跑一遍 OpenClaw 的一键扫描。当第一张属于你自己的认知图谱在屏幕上亮起时,你会感谢今天行动的自己。

