
摩根士丹利研报解读:中国AI的破局之道——以效率制胜,而非盲目求大
2
核心创新:DeepSeek的Engram模块,破解计算资源困境
DeepSeek最新推出的Engram模块,核心逻辑是将存储与计算解耦,通过"条件记忆"(Conditional Memory)机制,为大语言模型带来效率革新。
传统Transformer模型在处理静态事实(如"伦敦位于英国")时,需调用多层注意力机制和前馈网络进行复杂计算,造成GPU资源浪费。而Engram模块将静态记忆与动态推理分离,把模型的存储信息"库"卸载到通用DRAM(系统内存)中,GPU仅保留核心LLM,仅在需要时通过O(1)时间复杂度的查找机制调取静态信息,无需持续占用高昂的HBM(高带宽内存)。
这一创新带来三大核心价值:
1.缓解HBM依赖:对于HBM获取受限的中国市场,可减少对昂贵内存硬件的压力,无需升级HBM即可提升模型性能;
2.提升资源利用率:让现有GPU和系统内存架构发挥更大价值,在相同计算资源和参数规模下实现更高精度;
3.优化长文本处理:Engram负责处理局部固定模式,让注意力机制有更多"带宽"关注全局上下文,显著提升长文本检索与推理能力。
从技术原理来看,Engram通过哈希最近的令牌上下文(如2-3个令牌后缀),检索少量嵌入向量并通过门控机制与模型隐藏状态融合。这种结构支持内存容量随多GPU线性扩展,推理过程中还能实现异步预取,进一步提升效率。
关键数据:中国AI模型性能与资源效率双突破
中国主流AI模型与ChatGPT5.2性能对标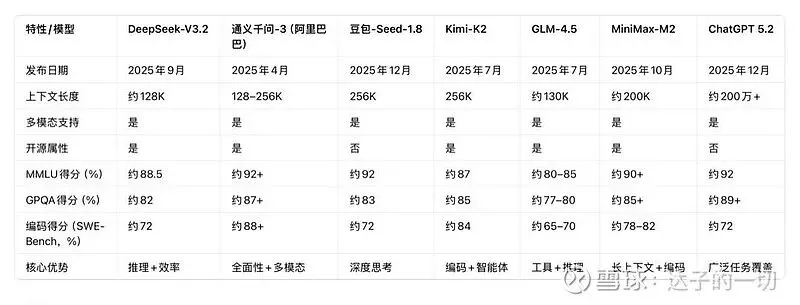
数据显示,中国头部AI模型在MMLU、GPQA等标准化基准测试中已接近ChatGPT5.2水平,部分模型在编码等细分场景甚至实现反超,而这一切是在计算成本仅为全球前沿模型几分之一的前提下达成的。
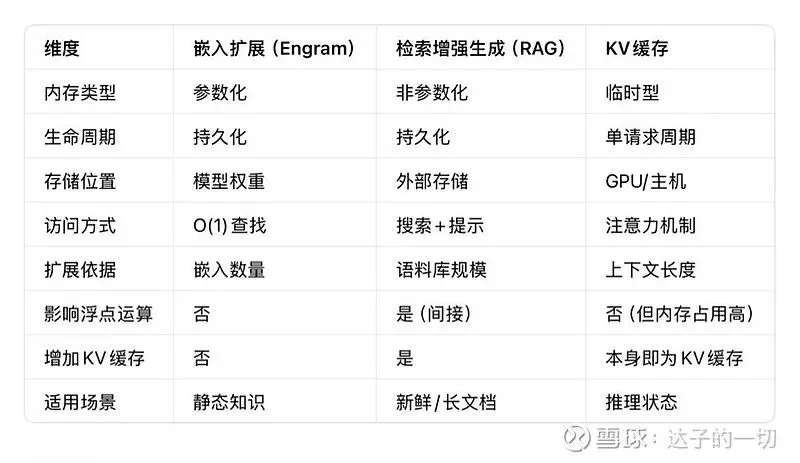
存储方案对比:Engram的效率优势
行业启示:中国AI的"约束驱动创新"之路
报告强调,过去两年中国AI模型在先进计算、硬件获取和训练规模均受限制的背景下,并未依赖暴力参数增长,而是通过四大效率创新实现弯道超车:
1.稀疏混合专家(MoE)架构;
2.训练与推理流程的极致优化;
3.长上下文注意力机制;
4.面向推理和编码任务的精准数据筛选。
这种"约束驱动创新"正在塑造更具韧性的中国AI生态——未来的AI竞争,不再是GPU集群规模的比拼,而是解决核心问题的效率之争。通过将部分模型增长从昂贵的神经计算转移到廉价、可扩展的嵌入内存(可卸载至CPU或系统内存),中国AI正在降低高端智能的边际成本,减少对无限制计算增长的依赖。
对于市场而言,这一趋势意味着AI产业的成本结构可能发生转变:基础设施支出将从GPU向内存倾斜,具备成本优势的内存和半导体本地化企业有望持续受益。
未来展望:DeepSeekV4值得期待
研报预测,DeepSeek下一代大语言模型V4将搭载Engram内存架构,在编码和推理能力上实现重大飞跃。与前代产品类似,
从长期来看,中国AI的发展路径正在证明:技术创新并非必须依赖顶级硬件,通过算法优化和系统设计创新,同样可以实现性能突破。这种以效率为核心的发展模式,不仅能规避硬件限制,更能构建可持续、可规模化的AI生态,为全球AI发展提供新的思路。
个人洞察:理性看待AI发展的"质"与"量"
在AI行业狂奔的这几年,"越大越好"的思维定式曾主导市场,但DeepSeek的实践让我们看到另一种可能——高效比庞大更有价值。对于企业而言,与其盲目追求参数规模和硬件投入,不如聚焦核心技术优化,找到适合自身的差异化路径;对于投资者来说,AI产业的投资机会正从单纯的硬件堆砌,转向算法创新、效率优化和供应链本地化等细分领域。
中国AI的发展历程也印证了一个朴素的道理:真正的创新往往诞生于约束之中。当外部环境倒逼行业跳出舒适区,反而能催生出更具生命力的技术方案和商业模式。未来,那些能在有限资源下实现效率最大化的企业,大概率会成为行业的长期赢家。
信息来源与风险提示
• 信息来源:摩根士丹利2
• 风险提示:本文章仅为研报内容翻译与解读,不构成任何投资建议。AI行业技术迭代速度快,存在技术路线变更风险;半导体供应链受全球产业环境影响较大,可能面临政策调整、产能波动等不确定性;市场竞争加剧可能导致企业盈利不及预期。投资者应结合自身风险承受能力,谨慎决策。

