题目:SagaScale: A Realistic, Scalable, and High-Quality Long-Context Benchmark Built from Full-Length Novels
作者:Guancheng Du, Yong Hu, Wenqing Wang, Yaming Yang, Jiaheng Gao
机构:清华大学、腾讯、北京大学
来源:arXiv:2601.09723v1
1. 研究背景与动机
当前的大语言模型(LLM)长文本(Long-Context)基准测试面临着一个“不可能三角”般的困境,难以同时兼顾以下三个关键维度:
任务真实性 (Task Realism):现有的许多基准(如 RULER, Needle-in-a-Haystack)依赖合成任务,难以反映真实世界中长文档理解的复杂性。 数据可扩展性 (Data Scalability):依赖人工标注的高质量基准(如 NovelQA)成本极高,数据量难以扩展。 数据质量 (Data Quality):现有的自动化生成方法往往局限于局部片段提问,问题复杂度低且易包含事实错误。
为了解决这一问题,本文提出了 SagaScale,旨在构建一个既具备全书宏观理解任务,又兼具低成本可扩展性与高质量的基准测试。
注:图片来源于原文
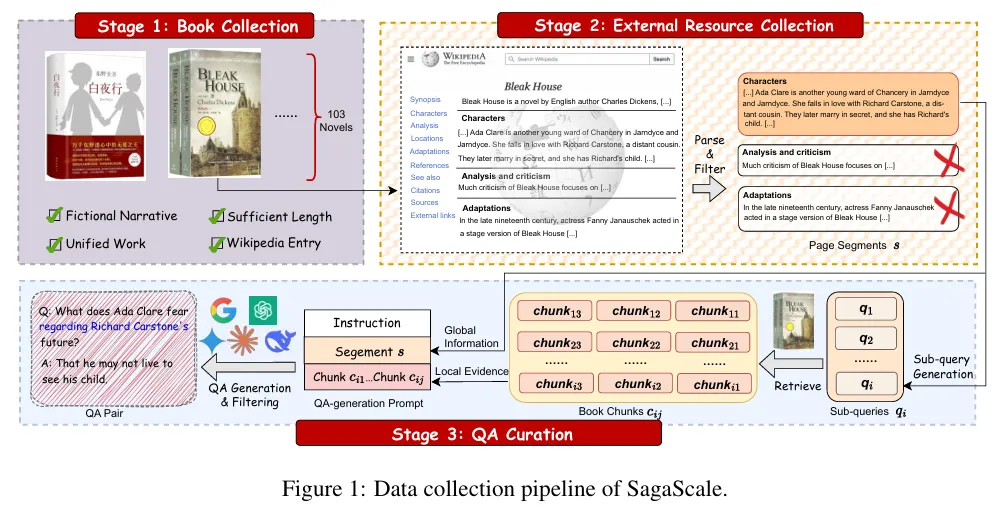
2. 核心方法:SagaScale
SagaScale 是一个双语(中英)长文本理解基准,其核心创新在于一套基于外部资源的自动化数据生成流水线。
数据构建流程:
数据源:选取全长小说(平均长度 >250k tokens)作为评估语料。 非对称生成机制:在生成问题阶段,利用维基百科等“外部资源”(External Resources)作为辅助,使模型拥有“上帝视角”来构建具有全局性、多跳推理(Multi-hop)的高难度问题。 严格评估设定:在评估阶段,被测模型仅能访问小说原文,无法获取外部摘要。这种信息不对称迫使模型必须通过阅读全书来推理答案。 质量控制:引入严格的过滤机制,包括防污染测试(闭卷回答测试),确保模型依靠的是上下文理解能力而非训练数据的记忆。
3. 实验结论
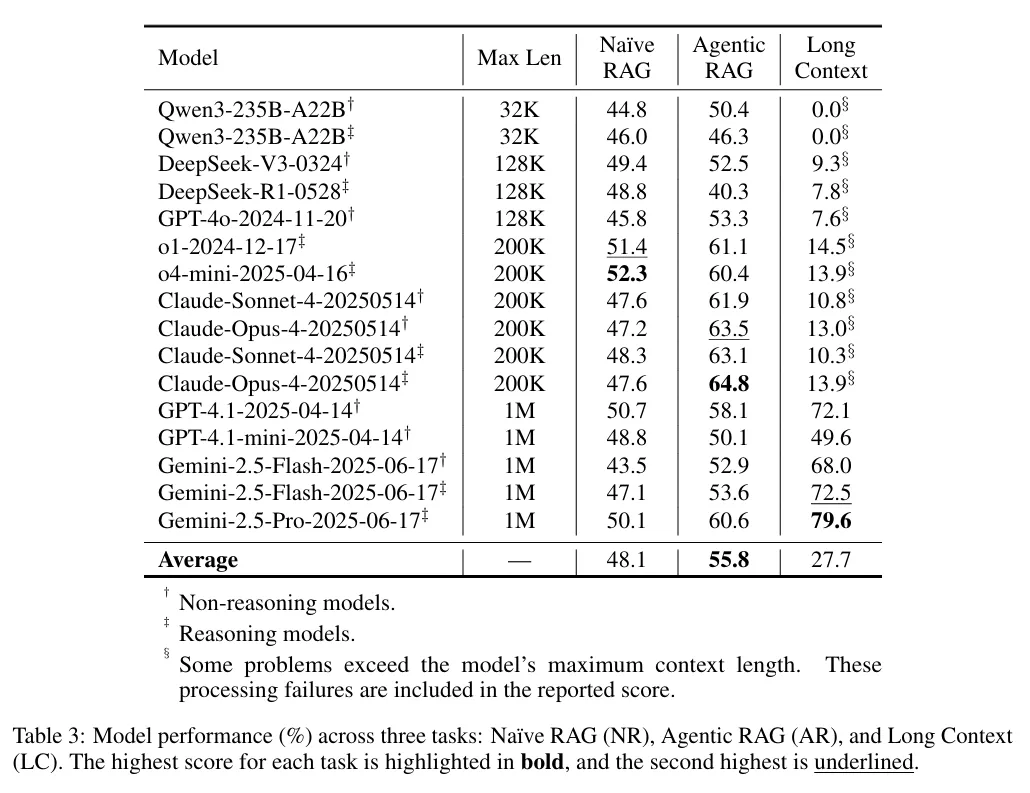
研究团队在 SagaScale 上评估了多种前沿 LLM 及三种长文本处理方法(Long Context, Naïve RAG, Agentic RAG),主要发现如下:
全文输入优于检索增强:在上下文窗口允许的范围内,直接将全书输入模型(Long Context)的效果通常大幅优于检索增强生成(RAG)方法。 Agentic RAG 优于 Naïve RAG:在检索方法中,多轮代理式检索(Agentic RAG)能有效缓解单次检索的瓶颈,表现优于朴素 RAG。 模型表现:大多数模型在处理超长文本时仍面临挑战,但 Gemini-2.5-Pro 展现出了优异的性能,尤其是在超长上下文窗口下的稳定性。
4. 展望与未来工作
训练数据转化:SagaScale 的生成流水线可用于大规模构建长文本训练数据,未来工作可探索简化过滤流程以适应训练集构建需求。 领域扩展:该方法论具有通用性,可进一步扩展至大型代码库理解、长视频/电影理解等其他长上下文领域。 多语言支持:目前仅覆盖中英双语,未来计划扩展至更多语种。
5. 深度点评
本文在长文本评估领域提供了一个扎实且具有启发性的新范式:
方法论创新:利用“信息不对称”(生成时看摘要,回答时看全书)巧妙解决了自动化基准中“问题过于局部化”的弊病,迫使模型进行真正的长距离推理。 揭示 RAG 局限性:实验数据量化证明了在连贯长文本叙事中,传统的切片检索(Chunking + Embedding)存在显著的语义断裂问题。这进一步佐证了扩大原生上下文窗口(Context Window)在解决长文本理解问题上的不可替代性。 严谨的防污染策略:针对公版书可能存在于预训练语料中的问题,文章采用了严格的闭卷测试过滤,这为评估模型真实的推理能力确立了高标准。
尽管目前生成的高质量 QA 对数量(1,124对)相对有限,且依赖维基百科限制了选材范围,但 SagaScale 无疑为下一代百万级 Context 模型的评估提供了一个贴近真实应用场景的标尺。
DOI / 原文链接:https://arxiv.org/abs/2601.09723v1